https://steadiness-193.tistory.com/112
판다스 - 지하철 공공데이터 분석 (2020년 1월 ~ 5월) : 2월의 유동인구 많은 일자, 역별 분석
데이터 불러오기 https://steadiness-193.tistory.com/109 판다스 - 지하철 공공데이터 분석 (2020년 1월 ~ 5월) : 전처리 데이터 출처 https://data.seoul.go.kr/dataList/OA-12914/S/1/datasetView.do 서울시 지..
steadiness-193.tistory.com
위에서 만들어낸 Feb 데이터프레임을 불러온다.

2월 14일에 승객이 많은 노선의 순위는?
groupby(['day', '노선명'])
2월 14일, 발렌타인데이를 살펴봐야하기 때문에
day로 그룹화하고
동시에 어느 노선이 2월 14일에 승객이 많은지도 보기 위해
노선명으로도 함께 그룹화하자.

잘 그룹화 되었으니
total을 기준으로 최댓값을 뽑아내면

일자와, 노선별 총 승객 수의 최댓값을 볼 수 있다.
원하는 날은 14일이기에 loc를 이용해 14일만 추출하면

위와 같이 나온다.
그냥은 보기 어려우니 정렬해서 그래프로 시각화해보자

너무나 당연하게 2호선이 압도적으로 높다.
2월 14일에 승객이 많은 노선에서, 승객이 '가장' 많은 역은?
groupby한 객체에
그냥 max를 전체적으로 쓰면 될까?
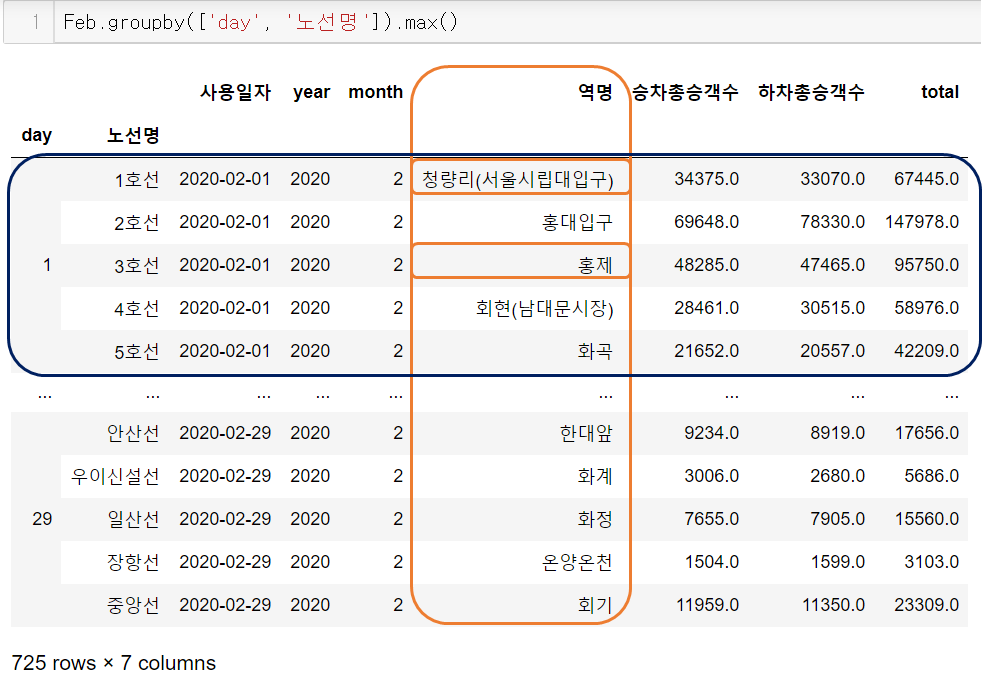
얼추 잘 나온 것 같다(?)
아니다. 여기엔 함정이 있다.
그룹별, 컬럼별로 최댓값을 구한 것이니
역명은 한글 기준으로 맨 뒤의 값이 나온 것이다.
예를 들어 1호선인 경우에는 승객 수가 가장 많은 서울역을 기대했지만
초성이 뒷 순서인 ㅊ의 청량리가 나온 것이다.
3호선의 경우에도 승객 수가 가장 많았을 고속터미널이 나오길 기대했다.
그러나 초성이 맨 뒤인 홍제가 나온 것이다.
따라서 total을 기준으로 그룹별 값이 제일 높은 행을 출력하려면

위 함수를 이용해야 한다.
자세한 내용은 아래 포스팅 참조
https://steadiness-193.tistory.com/104
판다스 - groupby : 멀티인덱스, idxmax 활용
데이터 만들기 위와 같은 데이터프레임이 있다. [목표 : Alpha, Key 멀티인덱스로 그룹화하여 Val 컬럼 기준 제일 높은 값의 인덱스를 이용해, 그 인덱스의 행만 추출] 우선 idxmax의 개념은 값이 제일
steadiness-193.tistory.com
발렌타인데이의 노선별 승객 수가 가장 많았던 역

get_maximum을 그룹별로 적용했다.
여기서 14일만 선택하면

원하던 valentine 데이터프레임을 만들 수 있다.
필요없는 컬럼을 제외하고
total컬럼을 기준으로 정렬해, 상위 10개 행만 보자

특이한 점은 서울에 있는 쟁쟁한 역들 사이에 부평역이 있다는 것이다.
서울역을 제외한 상위 10개 역에서
승차보단 하차가 더 많은 것도 볼 수 있다.
이 역시 역명을 기준으로 시각화하면

강남이 지나치게 압도적이다.
강남을 제외하고 다시 그려보자

발렌타인데이의 노선별 승객이 가장 많은 역들이다.
'Pandas > 실전' 카테고리의 다른 글
| 판다스 - 미국 주/지역별 인구밀도 계산 : merge, 인구밀도 계산 (0) | 2020.07.11 |
|---|---|
| 판다스 - 미국 주/지역별 인구밀도 계산 : 전처리, merge (0) | 2020.07.11 |
| 판다스 - 지하철 공공데이터 분석 (2020년 1월 ~ 5월) : 2월의 유동인구 많은 일자, 역별 분석 (0) | 2020.07.10 |
| 판다스 - 지하철 공공데이터 분석 (2020년 1월 ~ 5월) : 승객이 가장 많은 역/노선의 1월 분석 (0) | 2020.07.09 |
| 판다스 - 지하철 공공데이터 분석 (2020년 1월 ~ 5월) : 월별 승객이 제일 많은 역(노선) 찾기 (0) | 2020.07.09 |



