데이터 출처
UCI Machine Learning Repository
Moro, S., Cortez, P., & Rita, P. (2014). A data-driven approach to predict the success of bank telemarketing. Decision Support Systems, 62, 22-31
데이터 불러오기

위 데이터의 y컬럼을 살펴보면

no와 yes로 구성되어있다.
| yes | 은행 상품 가입 |
| no | 은행 상품 미가입 |
loan(대출) 컬럼

| yes | 대출이 있는 상태 |
| no | 대출하지 않음 |
| unknown | 확인할 수 없음 |
도식으로 정리해보면

찾아야하는 데이터는
가입여부에 따라 / 대출을 받은 사람들의 비율인 것이다.
가입여부에 따라
↓
y컬럼의 값에 따라 그룹핑

get_group을 이용해
yes_group과 no_group을 변수명으로, 두개의 데이터프레임을 얻어보자
yes_group (4640행)

no_group (36548행)

여기서 두가지 방법으로 비율을 찾을 수 있다.
대출을 받은 사람들의 비율
첫번째 방법. value_counts()이용

yes_group의 loan컬럼의 values_counts()의 결과를
yes_group_loan_status로 정의
no_group의 loan컬럼의 values_counts()의 결과를
no_group_loan_status로 정의
단, 절대적인 값으로는 수치를 비교하기 어려우니
각 시리즈를 각 시리즈의 합으로 나눠보자

이제 찾고자 했던 그룹별 대출비율이 나왔다.
이를 concat으로 연결하면 되는데 그전에
시리즈의 이름이 loan으로 동일하므로
이름을 바꾼뒤 concat을 진행하자
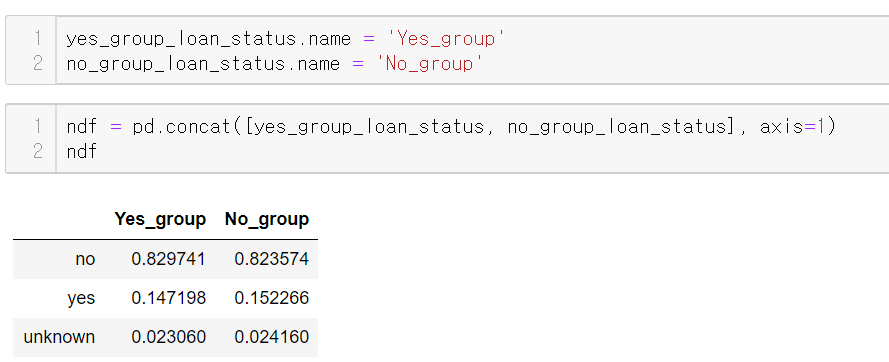
마지막으로 인덱스의 이름도 no, yes로 헷갈리니 loan으로 설정하면

한눈에 보기 편한 데이터프레임을 만들 수 있다.
두번째 방법. groupby 이용
위에서 만든 yes_group과 no_group을
다시 loan 컬럼 기준으로 그룹핑해서
size로 행의 개수를 구한다.

그러면 위에서 구했던 value_counts와 같은 값이 나온다.
동일하게 각 그룹의 size() 값을 size().sum()으로 나눠준다.

이를 다시 concat을 해주고 컬럼명을 넣어주면 완성된다.

결과 해석

대출이 있다면 은행상품에 가입을 덜 한다고 볼 수 있지만,
대출이 있는 사람이 은행 상품에 가입하는 비율과
대출이 있는 사람이 은행 상품에 가입하지 않는 비율은
약 0.005정도만 차이 난다.
유의한 차이가 있다고는 보기 어려운 수치다.
'Pandas > 실전' 카테고리의 다른 글
| 판다스 - 가상 쇼핑몰 고객 주문 데이터 : 전처리, Data cleansing, 메모리 효율화 (3) | 2020.07.20 |
|---|---|
| 판다스 - 연령과 직업, 은행 상품 가입간의 관계 (0) | 2020.07.16 |
| 판다스 - 고객데이터 시각화 : 히스토그램, 아웃라이어(이상치, 특잇값) 제거 (0) | 2020.07.15 |
| 판다스 - 고객데이터 시각화 : 나이대별 히스토그램, 문자열 컬럼 (0) | 2020.07.15 |
| 판다스 - 광고데이터 분석을 통한 비효율 키워드 추출 (0) | 2020.07.14 |



