반응형
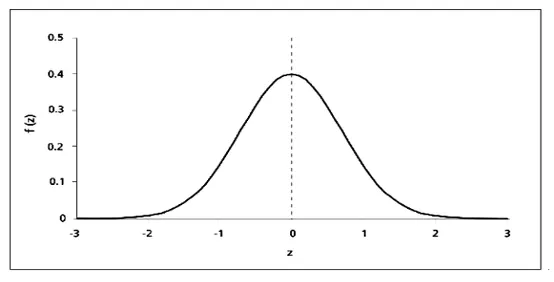
[Z-score]
데이터를 통계적으로 표준정규분포화
평균= 0, 표준편차= 1
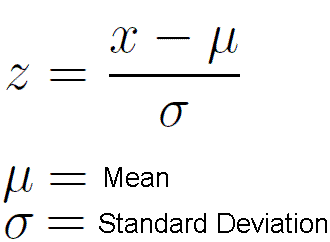
데이터(x)에서 평균을 뺀 값을
표준편차로 나눠준다.
데이터 불러오기 및 결측치 처리



결측치 처리는 아래 포스팅 참조
https://steadiness-193.tistory.com/239?category=961040
Machine Learning - 결측값 처리(Imputation) : mean
데이터 불러오기 categorical, numeric 컬럼 구분 리스트 제작 간단히, 자료형이 object라면 categorical이고 int나 float이라면 numeric이라 보면 된다. 방법1. for loop 이용 방법2. 직접 명시 + 리스트 이용..
steadiness-193.tistory.com
복사본 만들기

(1) Standard Scaler 불러온 뒤 정의

sklearn.preprocessing 패키지의 StandardScaler를 불러왔다.
이를 sdscaler로 정의한다.
numeric 컬럼 뽑아두기
values를 이용해 array로 뽑아둔다.
(2) Mean, Std 값 찾기

fit으로 평균값과 표준편차를 찾아낸다.
(3) Standard scale 처리한 데이터 리턴받기

transform을 이용하면 표준화된 값을 반환받을 수 있다.
(4) 결과 비교
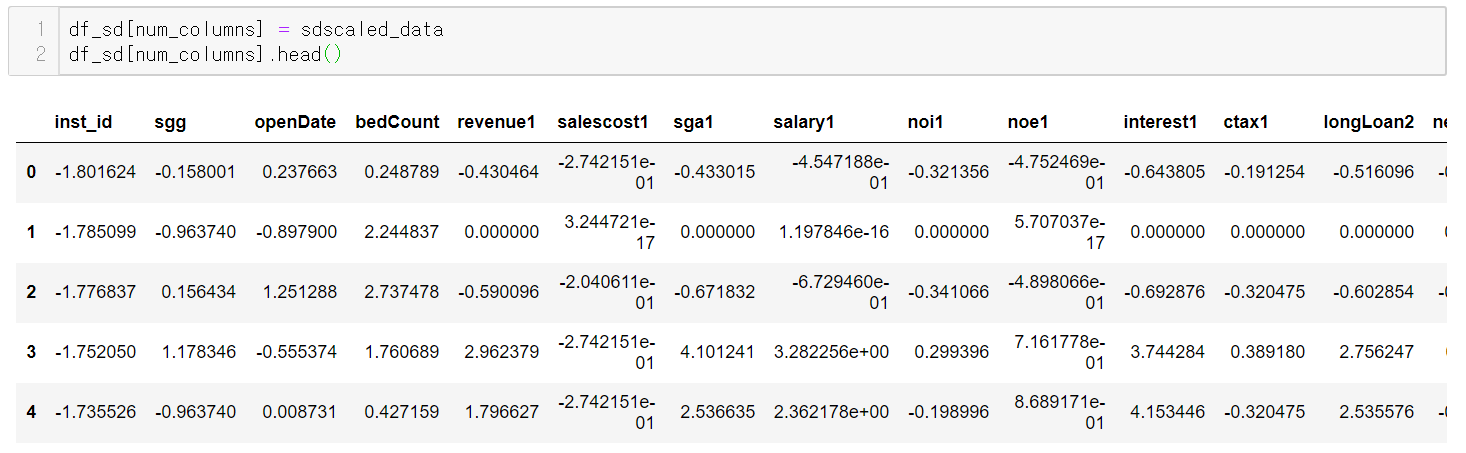
transform으로 표준화된 데이터를 기존 데이터와 바꾼다.

우측이 Standard Scaling이 완료된 하나의 컬럼을 그래프로 그린 것이다.
평균이 0, 표준편차가 1인 정규분포에 가까운 커널 밀도 그래프가 그려졌다.
반응형
'Machine Learning > 전처리(Preprocessing)' 카테고리의 다른 글
| Machine Learning - One-Hot Encoding (원핫 인코딩) (0) | 2020.08.26 |
|---|---|
| Machine Learning - Label Encoding (라벨 인코딩) (0) | 2020.08.26 |
| Machine Learning - Scaling : Min-Max Scaling (0) | 2020.08.26 |
| Machine Learning - 결측값 처리(Imputation) : median, mode (0) | 2020.08.26 |
| Machine Learning - 결측값 처리(Imputation) : mean (0) | 2020.08.26 |



