https://steadiness-193.tistory.com/294
Model Tuning - Stacking (스태킹_CV 기반)
https://steadiness-193.tistory.com/286 Validation - KFold www.kaggle.com/c/titanic/data Titanic: Machine Learning from Disaster Start here! Predict survival on the Titanic and get familiar with ML b..
steadiness-193.tistory.com
위 포스팅에선 train_test_split을 이용해서 라벨 후처리와 점수 측정까지 동시에 해보았다.
그러나 실제 대회에선 저렇게 나누지 않고 진행한다.
이번에도 익숙한 타이타닉으로 연습해보자
Titanic: Machine Learning from Disaster
Start here! Predict survival on the Titanic and get familiar with ML basics
www.kaggle.com
전처리는 아래 포스팅에 있으나
https://steadiness-193.tistory.com/290
Validation - OOF Ensemble (Out-of-Fold)
https://steadiness-193.tistory.com/286 Validation - KFold www.kaggle.com/c/titanic/data Titanic: Machine Learning from Disaster Start here! Predict survival on the Titanic and get familiar with ML b..
steadiness-193.tistory.com
행 삭제와 train_test_split을 진행하지 않는다.
또한 titanic 공식 점수 측정 방식인 정확도(accuracy_score)로 비교한다.
스태킹 하지 않은 기존 OOF Ensemble
(no_stacking_oof_rf_cv_0822)
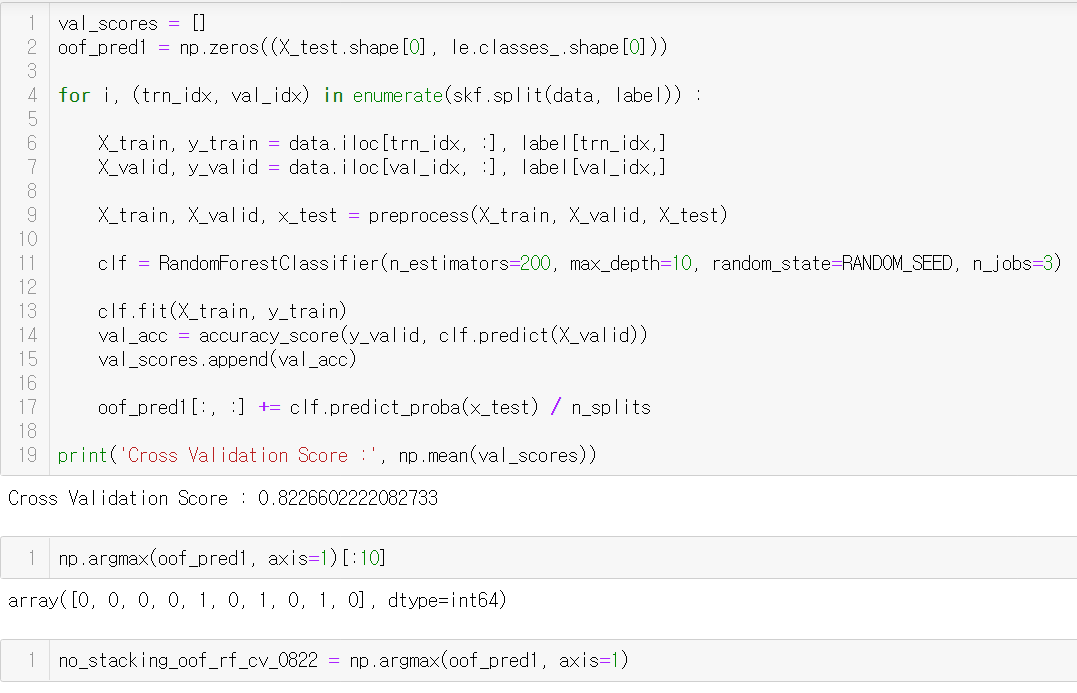
제출 점수 비교를 위해 만들어 둔다.
new_X_train, new_X_test 만들기


메타 모델로 바로 학습 및 예측
(stacking_straight_xgb)

new_X_train, new_X_test를 한번 더 OOF Ensemble
(stacking_oof_rf_cv_8058)

의아하게도 스태킹으로 만든 데이터셋으로 측정한 CV score가 더 낮게 나왔다.

위에서 만든 oof_train을 이용, (이진 분류이므로) 라벨 후처리까지 한 결과도 모아보자
(stacking_oof_rf_cv_8058_lablepp)
https://steadiness-193.tistory.com/291
Model Tuning - Label Postprocessing (라벨 후처리)
https://steadiness-193.tistory.com/286 Validation - KFold www.kaggle.com/c/titanic/data Titanic: Machine Learning from Disaster Start here! Predict survival on the Titanic and get familiar with ML b..
steadiness-193.tistory.com
scoring 함수는 위 포스팅 참조

new_X_train, new_X_test를 메타모델로 한번 더 OOF Ensemble
(stacking_oof_xgb_cv_7396)

더 이상하게도 메타모델로 측정한 cv 점수가 제일 낮다.
제출

결과 비교





CV 점수가 제일 높았던, 아무 것도 하지 않은 oof 앙상블의 점수가 0.77751로 가장 높았다.
그 다음이 스태킹과 라벨 후처리를 함께 한 0.75358이다.
스태킹한 데이터셋을 바로 메타모델로 학습 및 예측한 점수가 0.74162로 제일 낮았다.
결론적으로
결국 CV 스코어가 높아야하며, CV 점수가 높은 모델, KFold로 new_X_train과 new_X_test를 만들어야 한다.
'Machine Learning > 모델 튜닝(Model Tuning)' 카테고리의 다른 글
| Model Tuning - Stacking (스태킹_CV 기반) (0) | 2020.10.04 |
|---|---|
| Model Tuning - Label Postprocessing : 실전 적용 (0) | 2020.10.02 |
| Model Tuning - Label Postprocessing (라벨 후처리) (0) | 2020.10.02 |


