데이터 불러오기

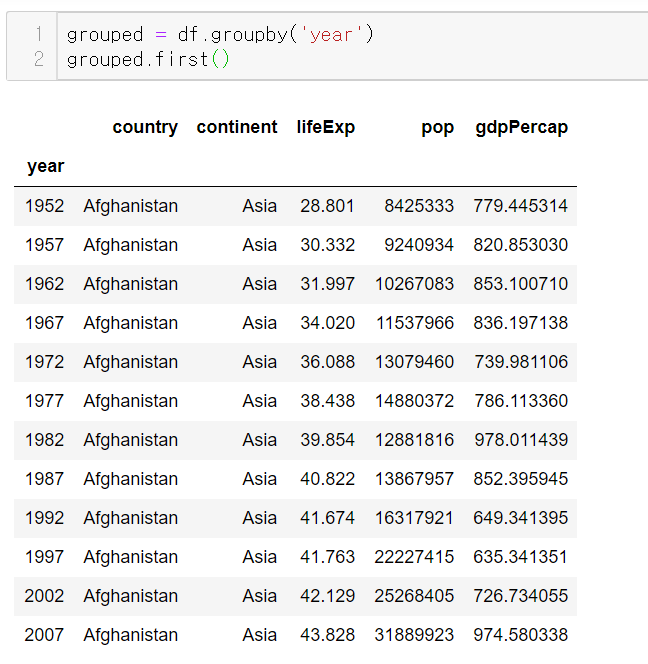
연도별로 그룹화되어있음을 확인했다.
데이터의 평균과 표준편차의 차이인 표준점수를 구하는 함수를 정의한다.

변환된 데이터의 평균값은 0, 표준편차는 1이된다.
데이터가 표준화되어 서로 다른 데이터를 쉽게 비교할 수 있다.
그룹별로 lifeExp(기대수명)에 대한 표준점수를 구해보자

굉장히 간단하다.
grouped의 lifeExp 컬럼에 transform을 사용자 정의함수로 적용하면 된다.
하나의 컬럼에 적용했기에 시리즈가 리턴된다.
transform의 장점이 원본 데이터프레임의 인덱스를 유지하는 것이므로
이를 열 추가에 활용하는 것이다.

새 컬럼이 추가되었다.
이 값은 연도별 기대수명의 표준점수이다.
또 다른 예시를 들어보자
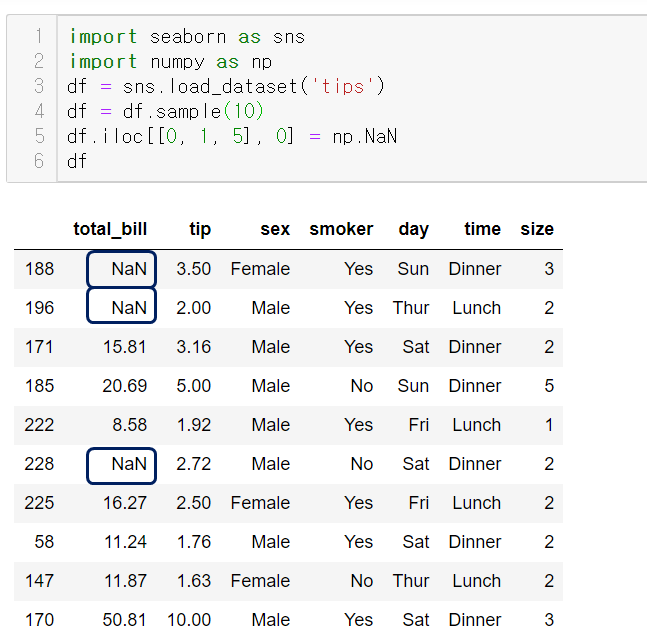
tips에서 total_bill의 일부 값을 NaN으로 변경했다.
그냥 total_bill의 평균값으로 채우면 되지 않나?
라고 생각할 수 있지만, 성비가 지금 여:남 = 3:7이다.
이 말 뜻은 성별에 따라 total_bill이 영향을 받을 수 있다는 것이다.
이에 성별로 데이터프레임을 그룹화했다.

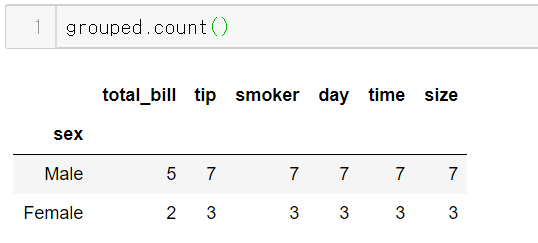
우려했던대로 성비가 불균형하다.
그룹별로 평균값을 보자
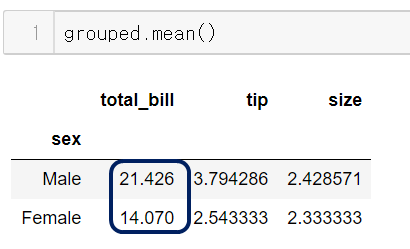
확실히 성별에 따라 total_bill의 평균값에 차이가 있다.
누락값을 그룹별 평균값으로 채울 수 있는 함수를 정의한다.

이를 그룹별 total_bill 컬럼에 transform 해보자

성별로 평균값이 다르게 채워졌다!
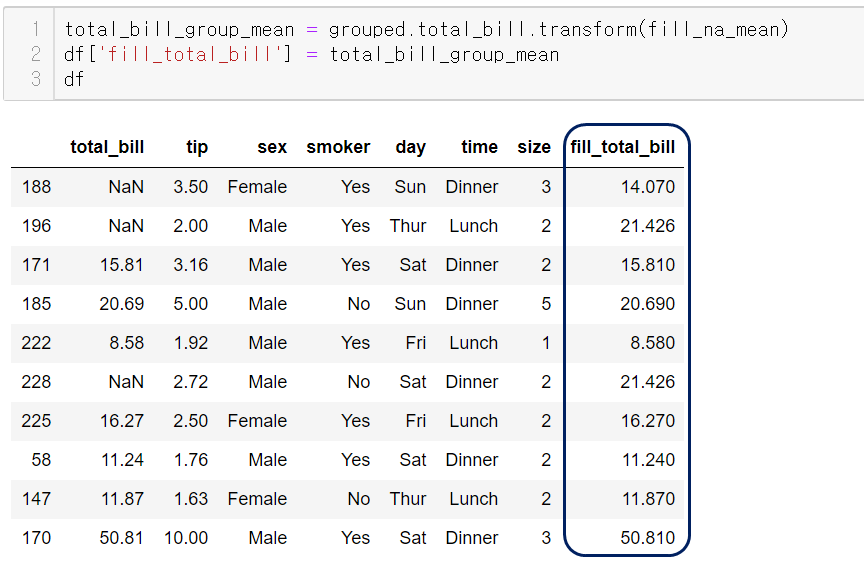
원본 인덱스를 유지하는 장점을 이용해
새로운 열로 추가했다.
그룹별 내림차순 순위 구하기
타이타닉 데이터
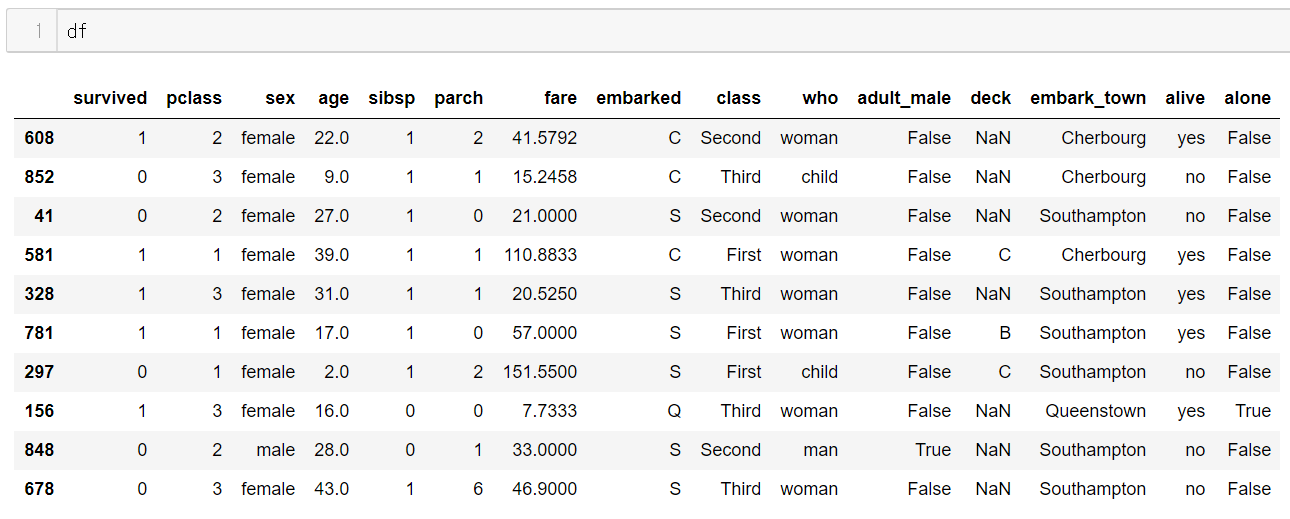
embarked 컬럼으로 그룹핑하자.

각 그룹별로 나이가 높은 순으로 순위를 구해보자

이렇게만 보면 알 수 없으니
여러 컬럼을 동시에 보면

각 그룹별로 나이가 높은 순으로 랭크값을 구해냈다.
이처럼 그룹별로 데이터 전처리는 필수적인 작업이라 할 수 있으며
필요한 메서드를 적재적소에 잘 활용해야한다.
'Pandas > 응용' 카테고리의 다른 글
| 판다스 - groupby : apply와 agg의 차이 (0) | 2020.06.23 |
|---|---|
| 판다스 - groupby : apply와 transform (차이) (0) | 2020.06.23 |
| 판다스 - groupby : transform (0) | 2020.06.23 |
| 판다스 - groupby : apply (0) | 2020.06.23 |
| 판다스 - groupby : filter (len, size, count) (0) | 2020.06.22 |



