https://steadiness-193.tistory.com/53
판다스 - pivot_table(피벗 테이블2)
피벗테이블 메서드(옵션)들을 상세히 살펴보자 데이터 불러오기 기본 피벗테이블 클래스별 / 성별별로 나이의 평균을 알 수 있다. values='age'컬럼을 넣었기 때문이다. aggfunc는 default가 평균값이다
steadiness-193.tistory.com
이전 포스팅의 피벗테이블에서 이어진다.
데이터 불러오기

xs 인덱서는 기본값으로 행 인덱스에 접근하고
축 값은 axis=0으로 자동 설정된다.
1. 행 출력
.xs(행 인덱스)

class에서 First에 해당하는 열만 가져왔다.
만약 여기서 female만 보고 싶다면?
.xs((행 인덱스, 행 인덱스))
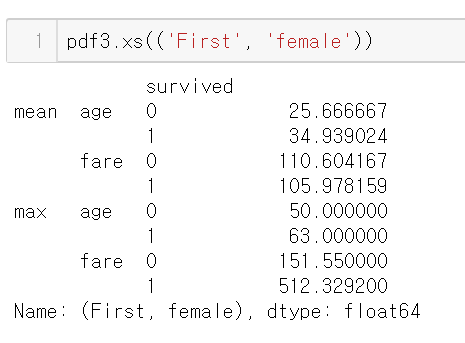
두개의 인덱스의 값을 튜플로 전달하면
First에서도 여자 승객의 데이터만 볼 수 있다.
그렇다면 만약에 class와 상관없이
여성의 데이터만 보고 싶다면
.xs('female')을 하면 될까?

안된다.
이때 필요한 것이 level 이다.
2. level

안쪽으로 들어올 수록 레벨이 높아진다고 생각하면 된다.
파이썬 공식처럼 레벨은 0부터 시작한다.
자, 이제 male의 데이터만 보고 싶다면
.xs(컬럼의 원소, level=컬럼명 / 레벨의 원소, level=값)

어떻게 하든 동일한 값이 나온다.
이 또한 마찬가지로
튜플을 이용해서
First의 female만 가져올 수 있다.

레벨에 컬럼명을 넣든 숫자형 레벨을 넣든 값은 동일하다.
숫자형과 문자형 레벨을 섞어도 같은 결과가 나온다.
3. 비교
- pdf.xs( ('First', 'female') )
- pdf3.xs(('First', 'female'), level=('class', 1))
이 둘은 어떤 차이가 있을까?
분명 First 클래스의 여성의 데이터를 가져오는 것은 같다.
pdf.xs( ('First', 'female') )
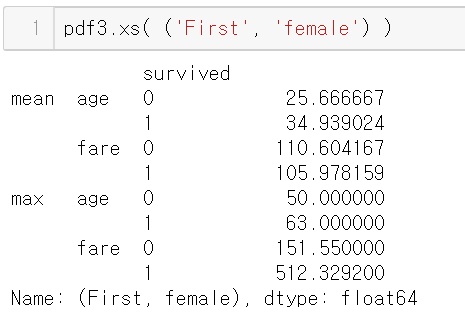
pdf3.xs(('First', 'female'), level=('class', 1))

이처럼
값들은 같아도
출력되는 형태가 시리즈 / 데이터프레임으로 다르다.
다음 포스팅에선
xs 인덱서를 이용해 컬럼을 출력하는 방법을 알아보자
'Pandas > 응용' 카테고리의 다른 글
| 판다스 - 교차일람표 : pd.crosstab() (0) | 2020.06.25 |
|---|---|
| 판다스 - pivot_table : xs 인덱서 2 (0) | 2020.06.25 |
| 판다스 - pivot_table (피벗 테이블2) (0) | 2020.06.25 |
| 판다스 - pivot_table (피벗 테이블) (0) | 2020.06.25 |
| 판다스 - 멀티인덱스 : loc, xs 인덱서 (0) | 2020.06.24 |



