판다스의 시계열 데이터는 주로
1. 시간 내에서 특정 순간의 타임스탬프(Timestamp)
2. 2007년 1월 전체 기간이나, 2010년 전체 같은 기간(Period)
위 두개를 많이 이용 한다.
물론 시간 간격과 실험 혹은 경과 시간이 있지만
위에 설명한 1,2번을 위주로 살펴보자
데이터 불러오기
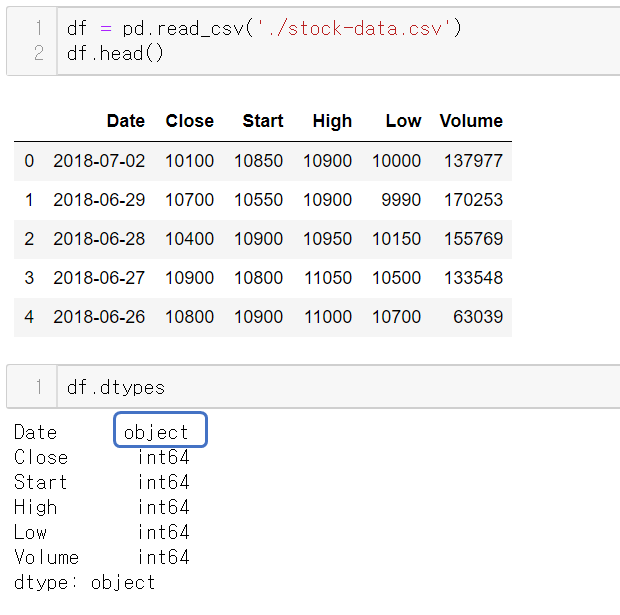
날짜 컬럼의 자료형이 문자열이다.
1. 문자열을 Timestamp로 변환
방법1. 불러올때 날짜로 파싱한다.

parse_dates를 이용해
Date 컬럼이 있는 순서를 주거나
Date 컬럼명을 리스트안에 넣어서 주면 바로 날짜 데이터로 바뀐다.
방법2. pd.to_datetime

판다스의 to_datetime 메서드를 이용해
새로운 컬럼을 만들며 그 컬럼의 자료형을 datetime64로 바꾼다.
2. 시계열 인덱스 만들기

datetime64 형인 컬럼을 인덱스로 설정한다.
그리고 이전에 있었던 기존 Date 컬럼을 삭제해보자

이렇게 해준 이유는
시간 순서에 맞춰 인덱싱 또는 슬라이싱이 편하기 때문이다.
시간으로 인덱싱

이렇게 2018년의 데이터만 보고 싶을땐
2018을 넘겨주면 된다.

참고1. 타임스탬프를 문자열로 (strftime)

[string from time]
시계열을 문자열로 바꾼다.
예시

참고2. 문자열을 타임스탬프로 (strptime)

[parse string to datetime]
문자열을 시계열로 파싱한다.
2010-11-21 이라는 '문자열'이 datetime으로 바뀌었다.
3. Timestamp를 Period로 변환
판다스 to_period() 함수 이용
object → to_datetime → to_period

우선 날짜같은 문자열을
pd.to_datetime을 이용해 Timestamp로 변환했다.
이제 Timestamp를 Period로 변환할 수 있는데
여기서 필요한 것이 바로 freq다.

freq의 옵션 'D' : 1일의 기간
freq의 옵션 'M' : 1개월의 기간
freq의 옵션 'Y' : 1년의 기간, 단 1년이 끝나는 12월이 기준
| 옵션 | 설명 | 옵션 | 설명 |
| D (day) | 1일 | Q (quarter end) | 분기말 |
| W (week) | 1주 | QS (quarter begin) | 분기초 |
| M (month end) | 월말 | A (year end) | 연말 |
| MS (month begin) | 월초 | AS (year begin) | 연초 |
| B (business day) | 휴일 제외 | H (hour) T (minute) S (second) |
1시간, 1분, 1초 |
'Pandas > 응용' 카테고리의 다른 글
| 판다스 - 시계열 데이터3 (날짜 분리) (2) | 2020.06.26 |
|---|---|
| 판다스 - 시계열 데이터2 : date_range, period_range (0) | 2020.06.26 |
| 판다스 - 교차일람표 : pd.crosstab() (0) | 2020.06.25 |
| 판다스 - pivot_table : xs 인덱서 2 (0) | 2020.06.25 |
| 판다스 - pivot_table : xs 인덱서 (0) | 2020.06.25 |



