https://steadiness-193.tistory.com/19
판다스 - 구간 분할(pd.cut)
데이터 불러오기 horsepower를 3구간으로 저출력 / 보통출력 / 고출력 나누고자 한다. 이때 pd.cut을 이용하는데 (데이터배열, 구간, 레이블이름, 경계 포함) 중 데이터배열과 구간은 필수 입력이다. in
steadiness-193.tistory.com
위 포스팅에서 사용한 get_dummies 와 비슷하다.
문제의 데이터를 살펴보자

장르 컬럼에 2개 이상의 값이 같이 있는 행도 있다.
최종 목표는
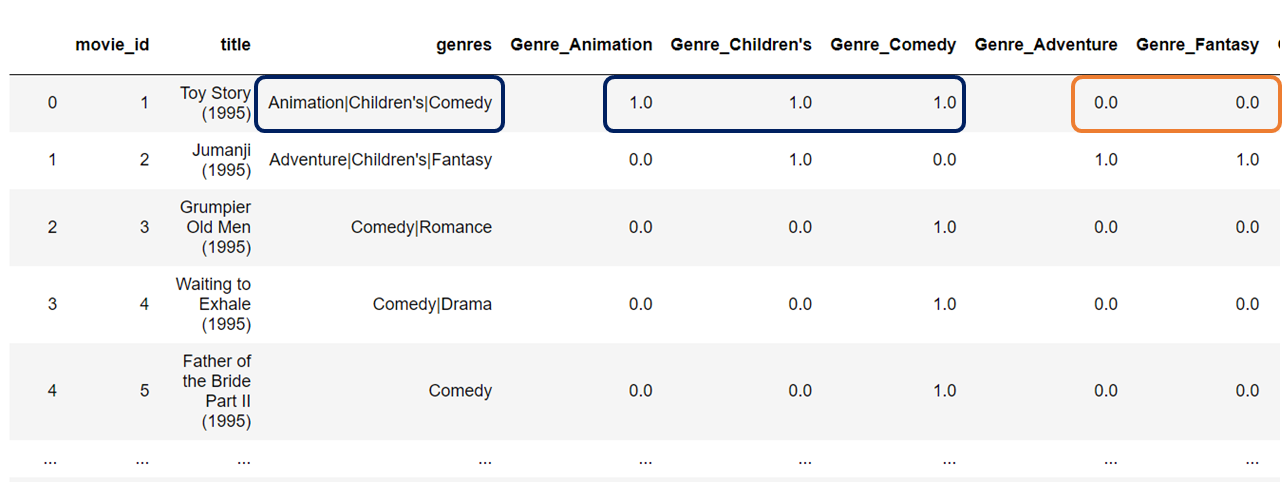
이렇게 만드는 것이다.
장르별 컬럼을 다 만들고
해당 장르에 속한다면 1을, 아니라면 0을 넣는 것이다.
1. 모든 장르 찾기

extend를 이용해 all_genres 리스트에
모든 장르 데이터를 담아냈다.
2. 중복 제거하기

pd.unique를 사용했으며
set을 이용해도 된다.
3. 제로 메트릭스 만들기
행 - 기존 데이터프레임의 행 개수
열 - 장르의 개수

4. 제로 메트릭스를 데이터프레임으로 만들기

컬럼명을 장르로 설정했다.
지금부터가 다소 헷갈릴 수 있다.
하나씩 살펴보자


첫번째 행의 장르 클럼을 가져와 split을 하면
세개의 원소가 담긴 리스트가 나온다.
여기서 이제 이용할 것이
get_indexer이다.


전체 리스트에서
해당 원소가 있는 인덱스를 찾을때 이용한다.
Animation과 Children's, Comedy는
장르 컬럼 리스트에서 0, 1, 2번째에 있다.
이를 for 구문에 넣으면

이렇게 나오니
이제 이를 활용하면 된다.
5. 데이터프레임에 0 또는 1로 값 채우기
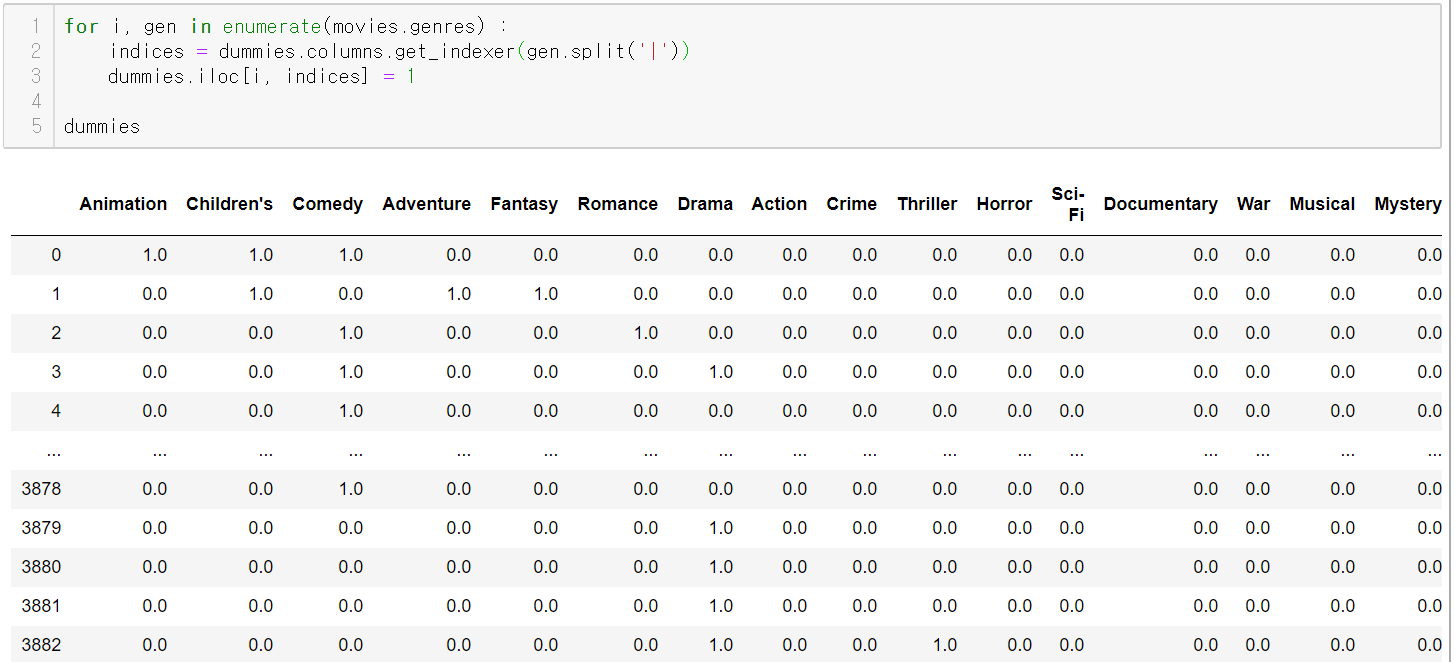
6. join으로 마무리
이제 위 데이터프레임을 기존 movies와 연결하면 된다.
인덱스가 동일하니 join을 이용하되
헷갈리지 않게 add_prefix도 이용한다.

장르 컬럼에 Genre_를 붙여서 join에 성공했다.
한 행만 살펴보면

잘 처리된 것을 확인할 수 있다.
'Pandas > 전처리' 카테고리의 다른 글
| 판다스 - 컬럼(열 or 변수)간 상관계수 : corr (0) | 2020.07.07 |
|---|---|
| 판다스 - 특잇값(outlier) 찾아내기 : Tukey Fences, Z-score (0) | 2020.06.29 |
| 판다스 - 특잇값(outlier) 처리하기2 (0) | 2020.06.27 |
| 판다스 - 특잇값(outlier) 처리하기 (0) | 2020.06.27 |
| 판다스 - 넓은 데이터 정리하기 : melt (0) | 2020.06.20 |



