데이터 출처
https://data.seoul.go.kr/dataList/OA-12914/S/1/datasetView.do
서울시 지하철호선별 역별 승하차 인원 정보
데이터 이용하기-서울시 지하철호선별 역별 승하차 인원 정보
data.seoul.go.kr
1. 데이터 불러오기
위의 2020년 1월부터 5월까지의 csv 파일을 subway 폴더에 저장해서
glob를 이용해 불러온다.
https://steadiness-193.tistory.com/27
판다스 - 여러 대용량 데이터 처리하기 : glob
이 다섯개의 csv 파일을 불러와 한꺼번에 보고자 한다. glob 라이브러리, glob 메서드 이용 glob 라이브러리의 glob메서드는 특정한 패턴의 이름을 가진 파일을 한번에 읽어들일 수 있다. 방법1. 하나��
steadiness-193.tistory.com

우선 1월의 데이터프레임을 맛보기로 봐보자

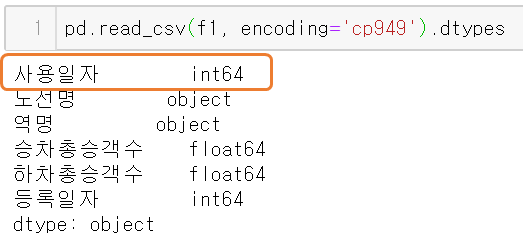
우선 고려해야할 것은 사용일자 컬럼이다.
이 컬럼은 날짜를 나타내고, 숫자형으로 등록되어 있다.
따라서 데이터를 불러올 때 parse_dates를 이용하는 것이 좋아보인다.
2. 데이터 합치기
이제 for loop를 이용해 리스트에 데이터프레임을 쌓고
concat을 이용해 합치면 된다.
단, csv 인코딩 문제가 있어서
불러올 때 encoding 파라미터를 이용해야, 글자의 깨짐이 없고 문제 없이 불러올 수 있다.

** 5월의 csv 파일은 utf-8로 해야 읽힌다.
encoding에 넣을 만한 코드는 아래와 같다.
euc-kr, cp949, latin_1, utf-8, utf-16
이제 df_list를 concat해주자

기존 인덱스가 유지되어 합쳐졌으니
인덱스를 초기화 해주자

3. 데이터 살펴보기
이제 이 데이터프레임의 정보를 살펴보면
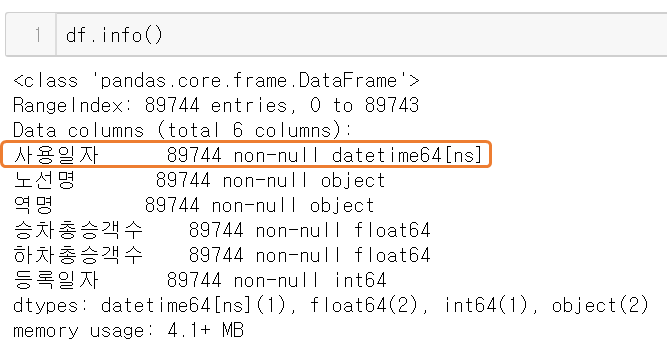
총 6개의 컬럼이 있고, 사용일자는 datetime으로 잘 불려왔다.
누락값이 있지는 않은지 확인해보자

다행히 누락값은 없다.
4. 불필요한 컬럼 삭제 및 연/월/일 컬럼 추가
사실 등록일자 컬럼은 필요가 없으니 삭제하고
사용일자의 컬럼에서 연, 월, 일을 얻어 하나씩 컬럼을 추가해보자


https://steadiness-193.tistory.com/60
판다스 - 시계열 데이터3 (날짜 데이터 분리)
날짜 데이터 분리 https://steadiness-193.tistory.com/22 판다스 - 열 분리하기 데이터 불러오기 연월일 컬럼을 연 / 월 / 일 세개의 컬럼으로 나눠서 보고 싶다면 방법1 : str.split() 1. 연월일 컬럼의 자료형..
steadiness-193.tistory.com
dt 연산자에 대한 내용은 위 포스팅 참조
마지막으로 한번 더 각 컬럼의 유형을 보면

연, 월, 일 컬럼이 정수형으로 잘 추가되었다.
5. 분석에 이용할 총 승객수 컬럼 추가

승차총승객수와 하차총승객수를 합친 total 컬럼을 추가했다.
'Pandas > 실전' 카테고리의 다른 글
| 판다스 - 지하철 공공데이터 분석 (2020년 1월 ~ 5월) : 승객이 가장 많은 역/노선의 1월 분석 (0) | 2020.07.09 |
|---|---|
| 판다스 - 지하철 공공데이터 분석 (2020년 1월 ~ 5월) : 월별 승객이 제일 많은 역(노선) 찾기 (0) | 2020.07.09 |
| 판다스 - 미국농무부 영양소 정보 : 각 영양소가 가장 많이 든 음식 (0) | 2020.07.08 |
| 판다스 - 미국농무부 영양소 정보 : 음식 그룹별 영양소 중간값, 최댓값 (0) | 2020.07.08 |
| 판다스 - 미국농무부 영양소 정보 (json 데이터 전처리2) (0) | 2020.07.08 |



