https://steadiness-193.tistory.com/105
판다스 - 미국농무부 영양소 정보 (json 데이터 전처리)
json 라이브러리를 이용해 읽어오기 이 db의 길이는 6636이다. 단, json데이터의 특성상 그냥 6636개의 데이터가 있다고 볼 수 없다. 그 이유는 db의 첫번째 값은 위와 같기 때문이다. Key Value id 단일값
steadiness-193.tistory.com
위 포스팅에서 만든 nutrients 데이터를 보자

총 375176행의 데이터로 영양소에 대한 정보를 담아두고 있다.
그러나 이 데이터프레임 하나만 가지고는 사실 어떤 분석을 하기 어렵다.
그래서 db의 다른 데이터와 병합을 해주려고 한다.
처음부터 차근히 보자
json 데이터 불러오기
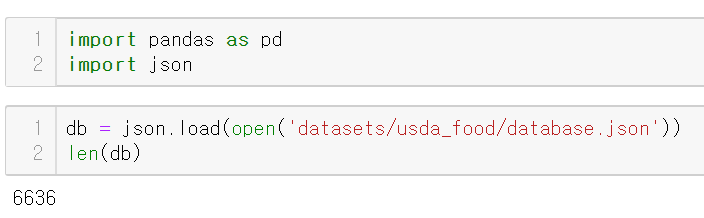

첫번째 db의 값들이다.
여기서 이제 가져올 것들은
병합을 위한 id와 음식과 관련된 description, group이다.

내가 원하는 키만 리스트에 담아두고
데이터프레임을 만들 때 columns에 키 리스트를 넣어주면 된다.
info는 음식과 그 음식의 그룹을 담아놓은 데이터프레임이다.

음식 그룹의 분포도 확인할 수 있다.
단, nutrients와 info는 컬럼의 이름이 겹친다.

컬럼의 이름이 같다고 데이터가 같은 것은 아니다.
왼쪽 nutrients의 description과 group은 영양소에 대한 정보이고
오른쪽 info의 description과 group은 음식의 종류와 음식의 그룹에 대한 정보이다.
헷갈릴 수 있으니 병합하기 전에 이름부터 바꿔주자

description → nutrient
group → nutgroup (nutrient group)

description → food
group → fgroup (food group)
이제 id컬럼 기준,
outer로 nutrients와 info 데이터프레임을 합쳐보자

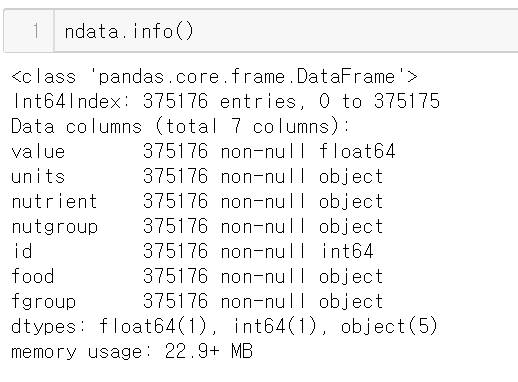
문제 없이 잘 merge 되었다.
'Pandas > 실전' 카테고리의 다른 글
| 판다스 - 미국농무부 영양소 정보 : 각 영양소가 가장 많이 든 음식 (0) | 2020.07.08 |
|---|---|
| 판다스 - 미국농무부 영양소 정보 : 음식 그룹별 영양소 중간값, 최댓값 (0) | 2020.07.08 |
| 판다스 - 미국농무부 영양소 정보 (json 데이터 전처리) (0) | 2020.07.08 |
| 판다스 - 미국 신생아 이름 : 이름의 성별 변화 (0) | 2020.07.05 |
| 판다스 - 미국 신생아 이름 : 마지막 글자의 변화 (0) | 2020.07.04 |



