나이키 스우시 드라이핏 캡 548533 : 네이버쇼핑
판매되는 상품의 수량에 대해 2주, 1개월, 3개월, 6개월 단위로 추이를 보여주는 정보입니다.
search.shopping.naver.com
위 네이버 쇼핑의 1페이지 내용을 긁어보자
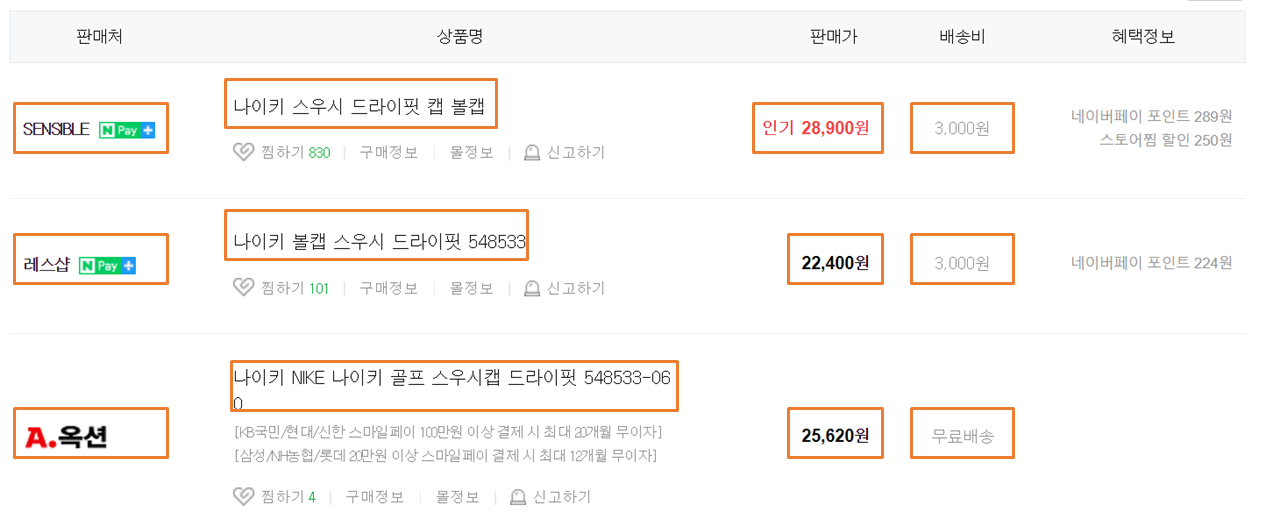
정확히는 판매처, 상품명, 판매가, 배송비 + 주소를 가져올 것이다.
1. BeautifulSoup으로 page_source 얻기

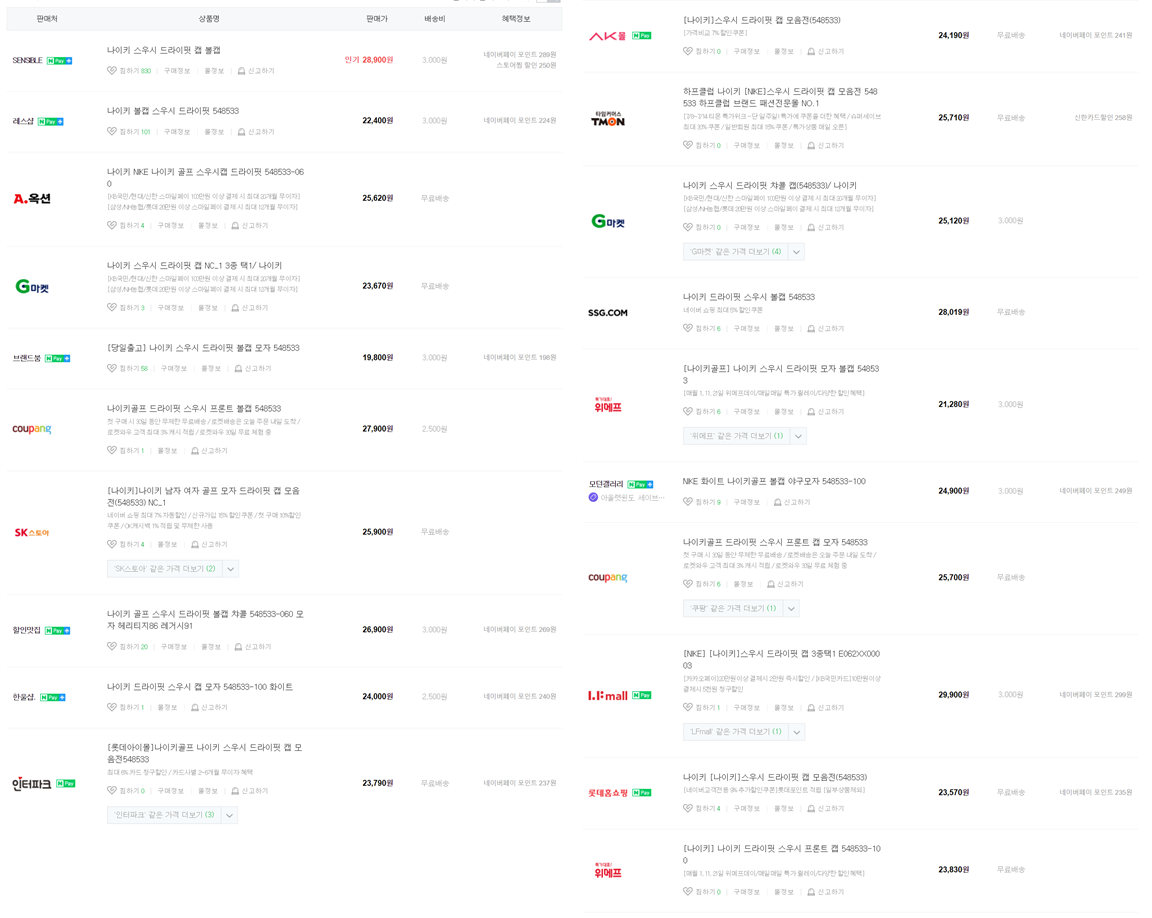
총 20개의 섹션이 있다.
이 20개를 먼저 찾아내야 한다.
2. 20개 찾기
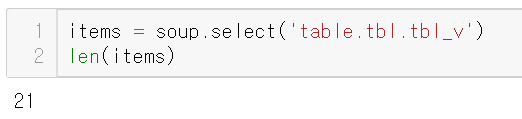
이상하게도 21개가 나왔다.
맨 처음 것을 보면

맨 상단의 컬럼 같은 것까지 가져왔다.
맨 처음 것을 제외하면 원하던 20개의 섹션을 얻을 수 있다.
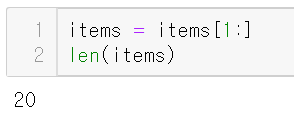
3. 판매처 찾기

그냥 글씨로 적혀있는 판매처와 이미지로 되어있는 판매처의 태그는 각각 다르다.
4. 상품명과 판매처 url 얻기

상품명과 판매처 주소는 섹션마다 크게 차이가 없다.
5. 가격 얻기
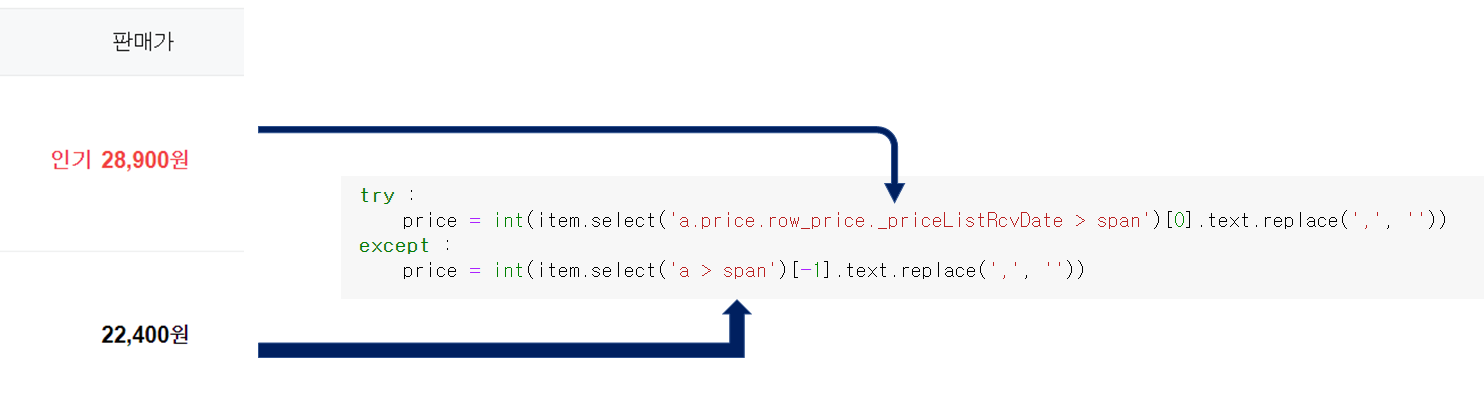
위의 섹션처럼 빨간색이 처리되어있고 한 부분은 a 태그에서 찾아가는 게 다르다.
일반적으로 검정으로 표시된 가격은 무난하게 a > span으로 찾을 수 있다.
가격은 모두 ,를 빼고 정수형으로 전환해서 가져온다.
6. 배송비 얻기

배송비가 있을 땐 3,000원을 정수형 3000으로 얻고
무료배송이면 그냥 무료배송을 가져온다.
7. 1페이지 긁어오기

url은 너무 길어 프린트 하지 않았다.
8. DataFrame으로 바꾸기

mall, title, price, delivery_fee, url을 리스트로 한번 감싼 뒤
result라는 빈 리스트에 append 해준다.
result는 총 20개로 잘 긁어와졌다.
이 result를 데이터프레임으로 바꿀 수 있다.

'Crawling (크롤링) > 네이버 쇼핑' 카테고리의 다른 글
| 크롤링 - webdriver(selenium)으로 네이버 쇼핑 크롤링하기 (4) | 2020.07.12 |
|---|---|
| 크롤링 - webdriver(selenium)으로 네이버 쇼핑 페이지 넘기기 (27) | 2020.07.12 |

