크롤링할 콘텐츠
나이키 스우시 드라이핏 캡 548533 : 네이버쇼핑
판매되는 상품의 수량에 대해 2주, 1개월, 3개월, 6개월 단위로 추이를 보여주는 정보입니다.
search.shopping.naver.com
https://steadiness-193.tistory.com/119
크롤링 : webdriver(selenium)으로 네이버 쇼핑 긁어오기
나이키 스우시 드라이핏 캡 548533 : 네이버쇼핑 판매되는 상품의 수량에 대해 2주, 1개월, 3개월, 6개월 단위로 추이를 보여주는 정보입니다. search.shopping.naver.com 위 네이버 쇼핑의 1페이지 내용을 �
steadiness-193.tistory.com
위 포스팅에서 만든 코드를
get_data 함수로 정의한다.
https://steadiness-193.tistory.com/118
크롤링 : webdriver(selenium)으로 네이버 쇼핑 페이지 넘기기
[2020년 7월 12일 기준] 향후 태그명이 달라질 수도 있음. 나이키 모자 네이버 쇼핑 페이지 나이키 스우시 드라이핏 캡 548533 : 네이버쇼핑 판매되는 상품의 수량에 대해 2주, 1개월, 3개월, 6개월 단��
steadiness-193.tistory.com
위 포스팅에서 만든 함수를
move_next 함수로 정의한다.
위 두개의 함수를 이용해서 모든 페이지의 원하는 내용을 긁어온다.

오류 없이 성공

총 217개의 데이터가 긁어졌다.
이를 df라는 변수명의 데이터프레임으로 바꾼다.

그리고 추후 분석을 위해
excel 파일로 저장한다.

to_excel은 url 때문에 에러 발생.
자세한 내용은 아래 포스팅 참조
https://steadiness-193.tistory.com/120
판다스 - 길이가 긴 데이터를 에러 없이 엑셀로 저장하기 : ExcelWriter
데이터프레임 위와 같은 데이터프레임의 컬럼을 보자 컬럼 중 url의 데이터가 너무 길다. 그래서 pd.to_excel을 이용하면 에러메세지가 뜬다. 실제로 Nike 엑셀 파일에 들어가봐도 url 컬럼은 비어 있�
steadiness-193.tistory.com
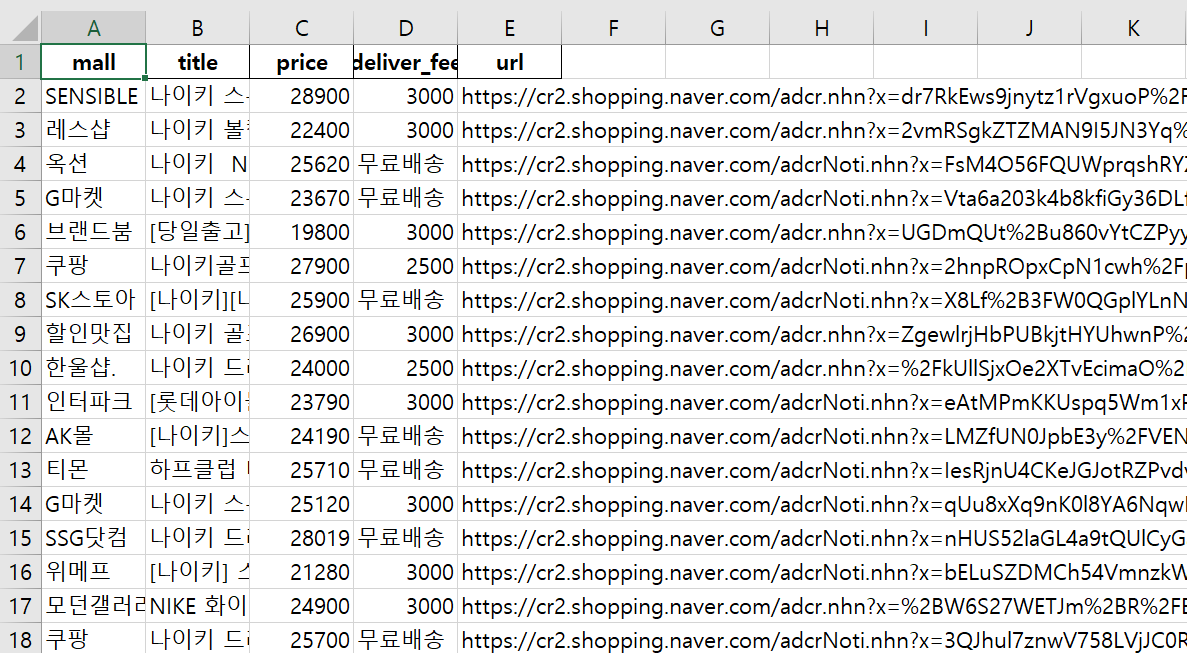
저장된 엑셀 확인
위 크롤링한 데이터에 대한 전처리와 분석은 아래 포스팅 참조
https://steadiness-193.tistory.com/124
판다스 - 네이버 쇼핑 크롤링 자료 : 전처리, 살펴보기
나이키 스우시 드라이핏 캡 548533 : 네이버쇼핑 판매되는 상품의 수량에 대해 2주, 1개월, 3개월, 6개월 단위로 추이를 보여주는 정보입니다. search.shopping.naver.com 네이버 쇼핑에서 위 나이키 모자에
steadiness-193.tistory.com
https://steadiness-193.tistory.com/125
판다스 - 네이버 쇼핑 크롤링 자료 : 분석
https://steadiness-193.tistory.com/124 판다스 - 네이버 쇼핑 크롤링 자료 : 전처리, 살펴보기 나이키 스우시 드라이핏 캡 548533 : 네이버쇼핑 판매되는 상품의 수량에 대해 2주, 1개월, 3개월, 6개월 단위로..
steadiness-193.tistory.com
'Crawling (크롤링) > 네이버 쇼핑' 카테고리의 다른 글
| 크롤링 - webdriver(selenium)으로 네이버 쇼핑 긁어오기 (0) | 2020.07.12 |
|---|---|
| 크롤링 - webdriver(selenium)으로 네이버 쇼핑 페이지 넘기기 (27) | 2020.07.12 |

