https://steadiness-193.tistory.com/124
판다스 - 네이버 쇼핑 크롤링 자료 : 전처리, 살펴보기
나이키 스우시 드라이핏 캡 548533 : 네이버쇼핑 판매되는 상품의 수량에 대해 2주, 1개월, 3개월, 6개월 단위로 추이를 보여주는 정보입니다. search.shopping.naver.com 네이버 쇼핑에서 위 나이키 모자에
steadiness-193.tistory.com
위 포스팅에서 전처리 완료한 데이터프레임을 이용한다.
df

mall 별로 그룹화 → grouped

mall 별로 total_price를 가장 저렴히 판매하는 곳 찾기

위 함수를 이용한다.
get_minimum 함수 적용 → group_df

이를 total_price 기준으로 오름차순으로 정렬하고
인덱스를 초기화 하면

mall의 고유값이 총 52개이기에
52개의 행이 나온다.
(오름차순 기준 상위 10개의 행만 캡쳐)
판매처가 많은 순으로 df 걸러내기
mall이 너무 많으니 판매처가 많은 순으로 몇개 걸러보자

여기서 10개 이상인 쿠팡까지만 판매처로 할당하자.

총 217개 중에 위메프부터 쿠팡까지의 합인 124의 비율은 약 57%이다.



위 코드들로 쿠팡까지의 배열을 얻었다.
isin 메서드를 사용해서 mall_cond를 만들고

그 mall_cond를 필터조건으로
filtered 데이터프레임을 만들자

filtered의 판매처는 위메프, G마켓, 옥션, 11번가, 인터파크, G9, 쿠팡만 있는 것이다.
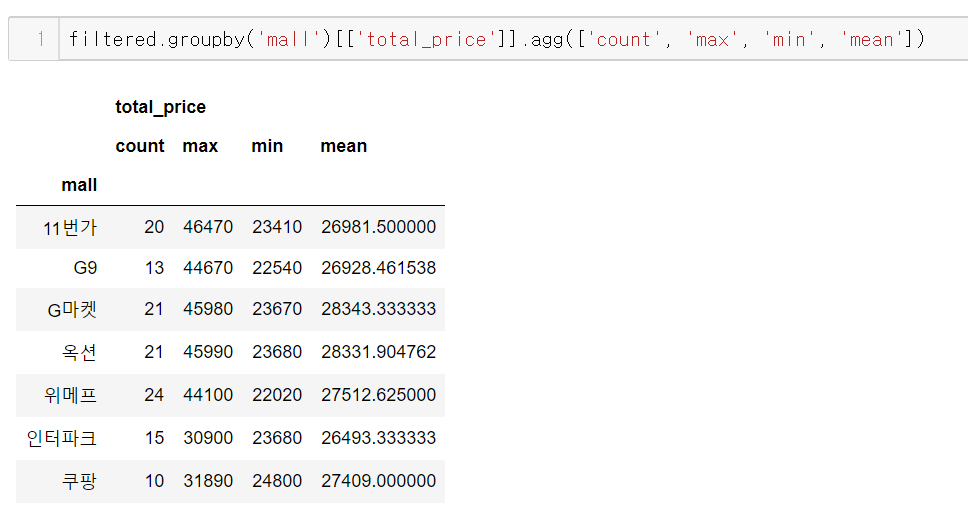
위 filtered를 다시 mall별로 그룹화해서 total_price의 여러 집계 값을 살펴보자
바이올린 플랏
filtered 데이터프레임을 판매처별, total_price를 바이올린 플랏으로
시각화해보자

위메프와 G9에서 저가 상품이 많아보인다.
가격의 격차가 크지 않은 곳은 쿠팡과 인터파크다.
평균적인 가격대는 주로 2~3만원 사이에 많이 분포되어있다.
filtered의 mall 그룹별로 비싸게 파는 3개 상품
최저 가격이 2만원대인데 굳이 비싼 제품은 그런 이유가 있을 것이다.
filtered의 mall별로 total_price를 내림차순하여 상위 3개씩만 뽑아보자.
함수 정의

위 어떤 것을 쓰든 상관 없다.
위 함수를 group객체에 apply 해보자

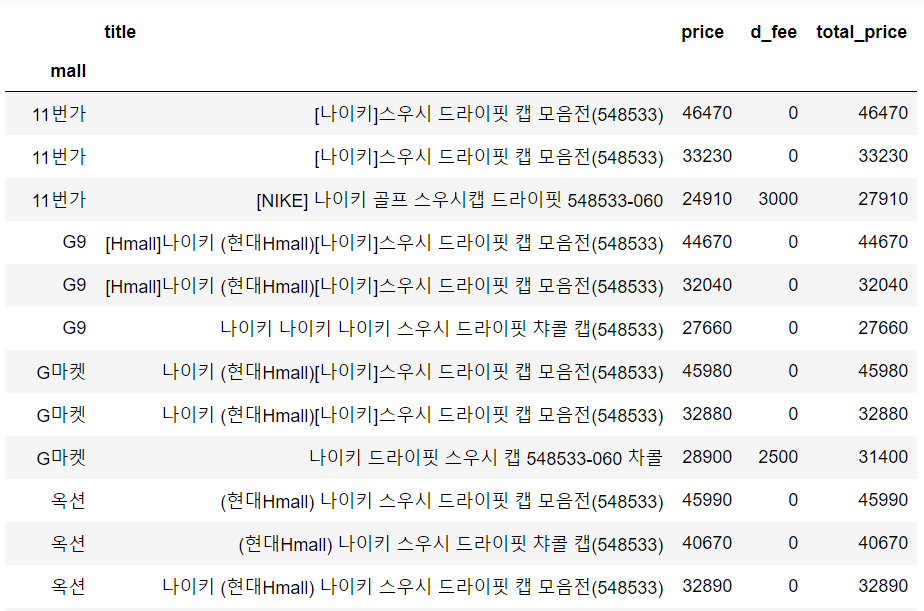

보기에 필요없는 컬럼은 따로 지워줬다.
주로 단일 제품보단 모음전이 많아보인다.
'Pandas > 실전' 카테고리의 다른 글
| 판다스 - 광고데이터 분석을 통한 비효율 키워드 추출 (0) | 2020.07.14 |
|---|---|
| 판다스 - 광고데이터 분석을 통한 중점관리 키워드 추출 (0) | 2020.07.14 |
| 판다스 - 네이버 쇼핑 크롤링 자료 : 전처리, 살펴보기 (0) | 2020.07.13 |
| 판다스 - 미국의 연도별 인구밀도 변화 (0) | 2020.07.11 |
| 판다스 - 미국 주/지역별 인구밀도 계산 : merge, 인구밀도 계산 (0) | 2020.07.11 |



