https://steadiness-193.tistory.com/116
판다스 - 미국 주/지역별 인구밀도 계산 : merge, 인구밀도 계산
https://steadiness-193.tistory.com/115 미국 주/지역별 인구밀도 계산 : 전처리, merge 총 3개의 데이터프레임이 있다. 1. 주 / 나이 / 연도 / 인구 수를 담은 population 2. 주와 주 이름의 약자를 담은 abbrev..
steadiness-193.tistory.com
위 포스팅의 final 데이터프레임을 이용한다.
위 포스팅에선 USA의 행을 삭제했지만 지금은 USA의 행을 이용할 것이다.

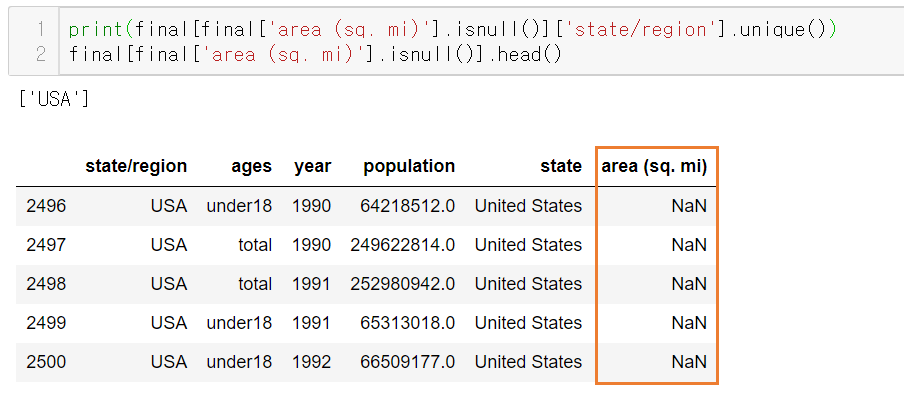
현재 USA의 전체 면적만을 모르고 있는 상태다.

USA의 행만 따내와서 usa 변수에 넣어주자
반대로
final 데이터프레임에선 USA 행을 잘라낸 뒤

인덱스를 초기화했다.
우선 final 데이터프레임의 컬럼을 살펴보면
| 주 (state) | Alabama, Ohio, New York 등 총 52개의 고유값 |
| 나이 (ages) | 18세 미만, 전체 총 2개의 고유값 |
| 연도 (year) | 1990년부터 2013년까지 총 24개의 고유값 |
위와 같이 세개의 컬럼으로 그룹화 가능해 보인다.
usa 데이터프레임 또한 위와 같지만
한가지 다른 것은 state가 USA 하나 뿐이라는 것이다.
즉, 나이와 연도별 그룹의 합을 하면 자연스럽게 state들의 합이 구해진다는 것이다.

전체 나이의, 1990년의 모든 주의 면적의 합이다.
사실, USA의 전체 면적은 변할리가 없다.
다시 말하면 3790399 값이 USA의 면적인 것이다.
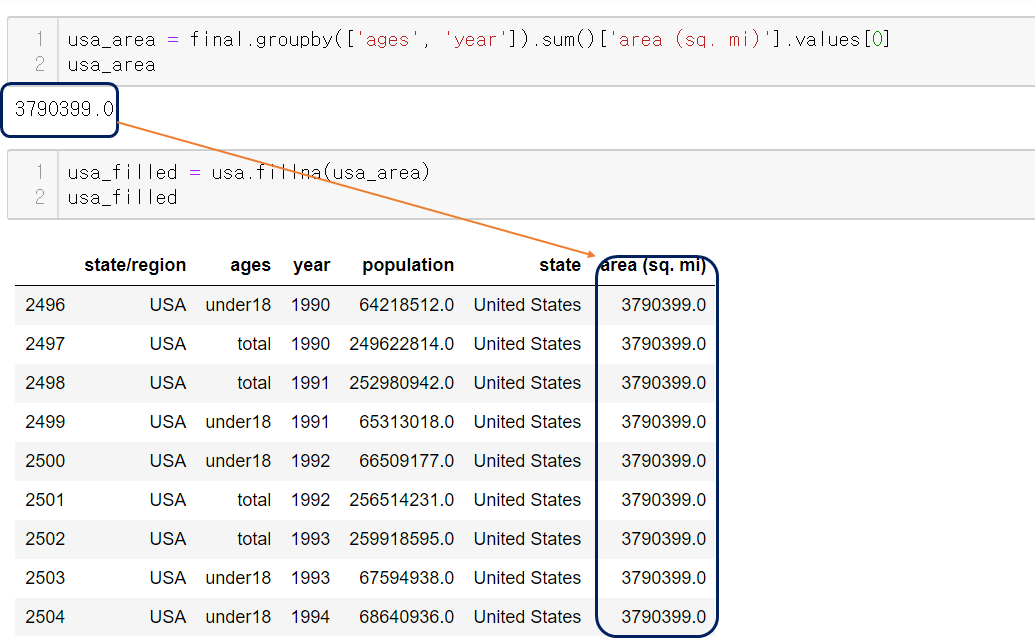
groupby 객체의 첫번째 값을 usa_area 변수에 넣고
usa 데이터프레임의 누락값에 fillna 메서드를 이용해서 그 값을 넣어준다.
그리고 final에서 usa를 떼온 것이기 때문에
다시 concat으로 붙여주면 된다.

USA의 전체면적이 잘 채워진 것을 볼 수 있다.
이제
인구밀도를 구해주고

인구밀도 시리즈 (density)를 result의 맨 마지막 컬럼으로 추가해준다.

정말 마지막으로 ages의 total과 USA의 데이터만 뽑아내
인구밀도를 그래프로 그리면

위와 같이 나오게 된다.
1990년부터 꾸준하게 증가한 것을 볼 수 있다.
'Pandas > 실전' 카테고리의 다른 글
| 판다스 - 네이버 쇼핑 크롤링 자료 : 분석 (0) | 2020.07.13 |
|---|---|
| 판다스 - 네이버 쇼핑 크롤링 자료 : 전처리, 살펴보기 (0) | 2020.07.13 |
| 판다스 - 미국 주/지역별 인구밀도 계산 : merge, 인구밀도 계산 (0) | 2020.07.11 |
| 판다스 - 미국 주/지역별 인구밀도 계산 : 전처리, merge (0) | 2020.07.11 |
| 판다스 - 지하철 공공데이터 분석 (2020년 1월 ~ 5월) : 발렌타인데이 분석 (0) | 2020.07.10 |



