데이터 불러오기
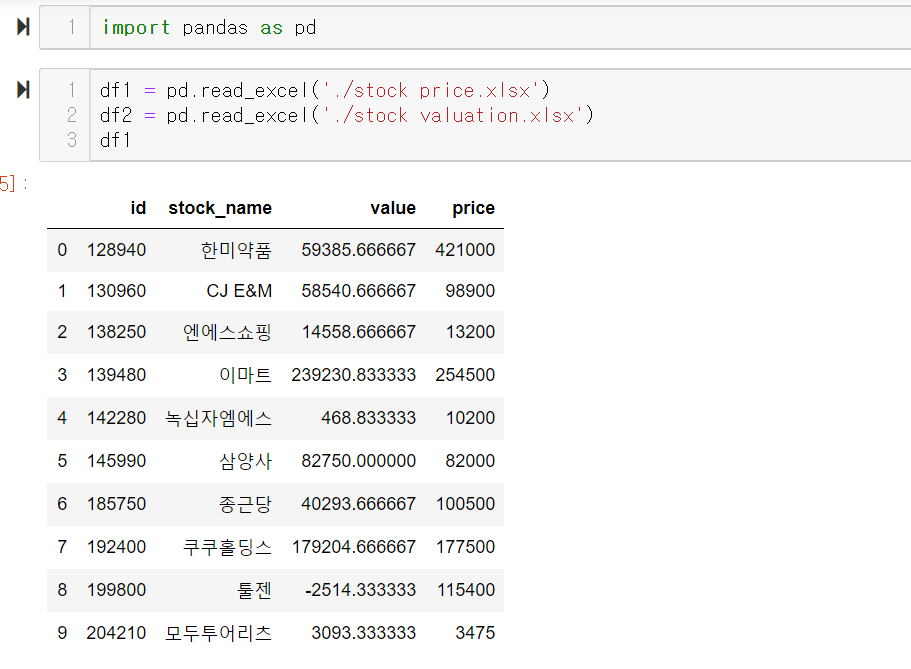
df1의 행은 총 10행, 열은 id, stock_name, value, price

df2의 행도 총 10행, 열은 id, name, eps, bps, per, pbr
df1과 df2의 겹치는 컬럼은 id컬럼 하나뿐
merge하기 전, id가 겹치는 행만 보고 싶다면?
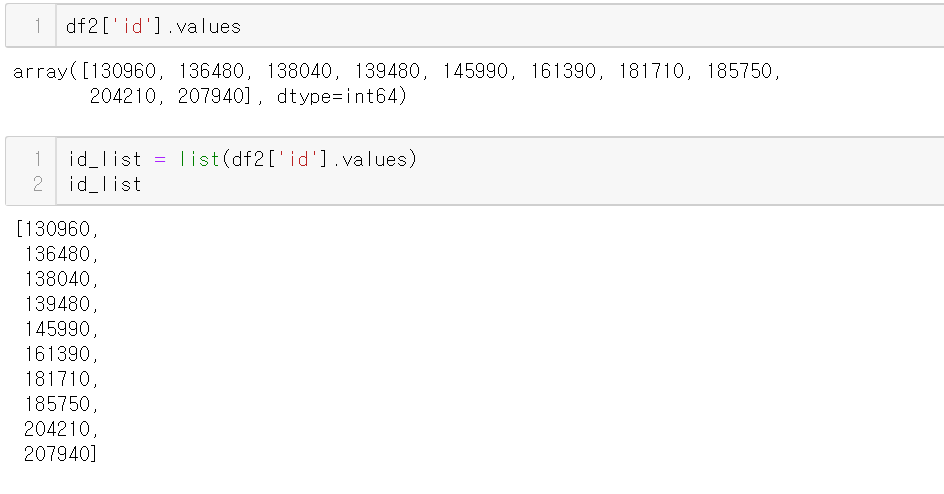
df2의 id리스트를 id_list라는 변수로 가져왔다.

isin()을 이용하여 df1의 아이디가 id_list에 들어있는지에 대한
True/False 리스트를 가져왔고
이를 불린 인덱싱하여 df1과 df2의 아이디가 겹치는 행을 볼 수 있다.
df1을 기준으로 불린 인덱싱을 했으므로 기준 테이블은 df1임을 볼 수 있다.
(컬럼이 df1의 컬럼)
이를 더 간단하게 하는 방법은 그냥 merge를 이용하는 것.
merge, (on=None, how='inner')

on=None과 how='inner'는 기본 옵션이다.
on=None은 두 데이터프레임에 공통으로 속하는 모든 열을 기준으로 병합한다.
how='inner'는 옵션이 되는 기준열의 데이터가 양쪽 데이터프레임에
공통으로 존재하는 교집합일 경우에만 추출한다.
즉, 공통 컬럼에서 겹치는 데이터의 행만 가져오는 것이다.
아까와 다른 것은 df2의 컬럼도 보이며 인덱스도 초기화 된 것이다.
merge, (on='id', how='outer')


두 데이터프레임의 공통 열 중에서 id 열을 키로 병합했다.
how='outer' 옵션은 기준이 되는 id열의 데이터가 어느 한 쪽에만 속하더라도 포함된다는 뜻이다.
예를 들어 0번 행은 겹치는 id가 없지만 id가 존재하므로 df1의 행이 보이고,
겹치는 데이터가 없는 df2의 행은 NaN으로 표시되었다.
merge (how='left', left_on='column', right_on='column')

how='left' 옵션 설정 시 왼쪽 데이터프레임의 키 열에 속하는 데이터 값을 기준으로 합친다.
그러니까 df1은 그대로 다 살리겠다는 뜻이다.
다만 기준이 되는 열은 left_on 옵션에서와 같이 'stock_name'컬럼이며
df2의 병합이 되고자하는 컬럼은 'name'인 것이다. (right_on='name')
1번 행을 보면 둘 다 CJ E&M을 가지고 있으므로 NaN 없이 잘 병합된 것을 볼 수 있다.
** id열의 경우 양쪽 데이터프레임에 모두 존재하므로 id_x와 id_y로 구분되어 표시되었다.
merge, (how='right', left_on='column', right_on='column')
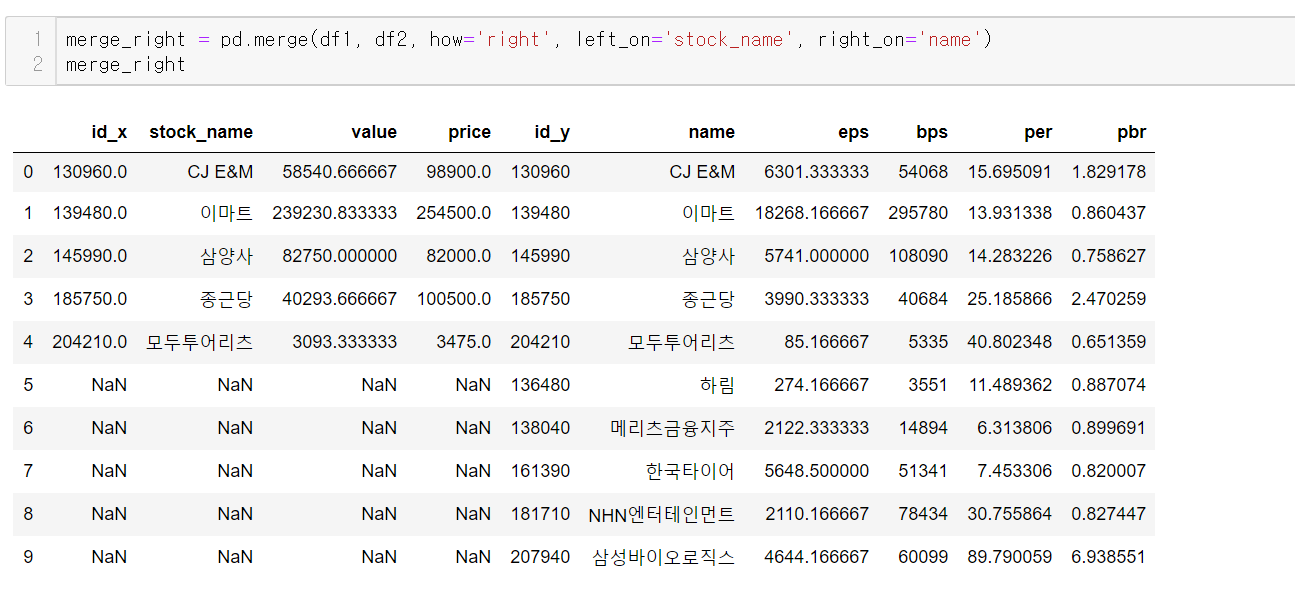
바뀐 것은 how뿐이다.
즉 df2는 다 살리겠다는 것이며 이름이 같다면 그 행은 NaN 없이 잘 병합되는 것이다.
** id열의 경우 양쪽 데이터프레임에 모두 존재하므로 id_x와 id_y로 구분되어 표시되었다.
'Pandas > 응용' 카테고리의 다른 글
| 판다스 - apply, applymap, pipe(응용1) (0) | 2020.06.21 |
|---|---|
| 판다스 - apply, applymap, pipe(2) (0) | 2020.06.20 |
| 판다스 - apply, applymap, pipe(1) (2) | 2020.06.20 |
| 판다스 - 여러 대용량 데이터 처리하기 : glob (0) | 2020.06.20 |
| 판다스 - 인덱스로 데이터프레임 병합 : merge, join (0) | 2020.06.20 |



