반응형
Gradient Boosting 알고리즘 기반의 단점을 보완한 xgboost에도 아쉬운 점이 있다.
바로, 여전히 속도가 느리다는 것이다.
이를 다시 보완하기위해 나온 것이 LightGBM이다.
[LightGBM]
XGboost보다 가볍고 더 나은 성능을 보이며 메모리도 더 적게 사용한다.
XGboost의 균형 트리 분할 방식 (level-wise)가 아닌 리프 중심 분할 방식 (leaf-wise)을 사용해
비대칭적 트리를 형성하므로 균형을 잡기 위한 연산을 하지 않는다.

lightgbm의 장단점
| 장점 | 단점 |
| xgboost의 장점을 차용한다. | 데이터의 양이 적다면 과적합될 가능성이 있다. (leaf-wise) |
| xgboost 보다 빠르고 좋은 성능, 더 적은 메모리 |
https://steadiness-193.tistory.com/257
Machine Learning - valid와 test를 train으로 전처리
https://steadiness-193.tistory.com/256 Machine Learning - train_test_split https://steadiness-193.tistory.com/253 Machine Learning - 랜덤으로 train과 test로 나누기 데이터 불러오기 seaborn의 iris 데..
steadiness-193.tistory.com
위 포스팅에서 만든 데이터셋을 이용한다.
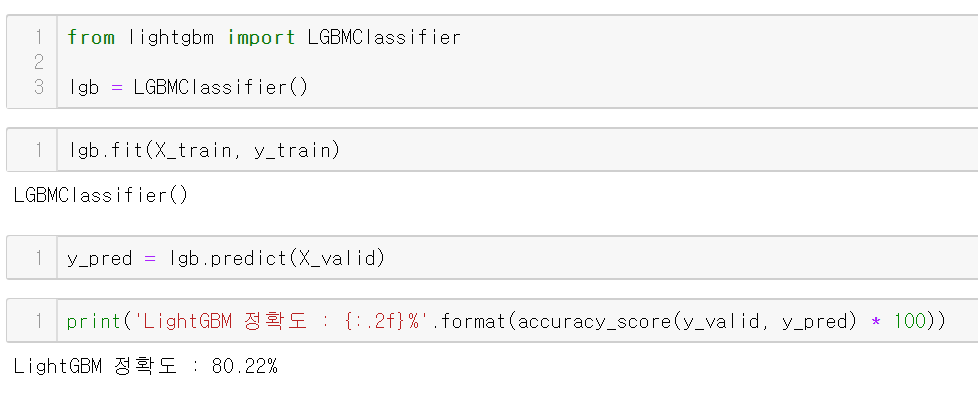
파라미터 없이 그냥 진행한 결과 약 80%의 정확도를 보여준다.
LightGBM 파라미터
n_estimatiors : 트리의 갯수, 높을 수록 정확도가 높아지나 시간이 오래 걸린다. (int)
n_jobs : 병렬처리 여부, -1을 입력하면 컴퓨터에 존재하는 모든 코어를 사용한다.
random_state : 결과를 고정시킴, Seed Number와 같은 개념 (int)
max_depth : 생성할 결정 트리의 깊이 (int)
learning_rate : 훈련양, 학습할 때 모델을 얼마나 업데이트 할 것인지 (float)
colsample_bytree : 열 샘플링에 사용하는 비율 (float)
subsample : 행 샘플링에 사용하는 비율 (float)
reg_alpha : L1 정규화 계수 (float)
reg_lambda : L2 정규화 계수 (float)
boosting_type : 부스팅 방법 (gbdt / rf / dart / goss)

규제를 적용하니 정확도가 약 1.5%p 상승했다.
변수 중요도 (Feature_importance)
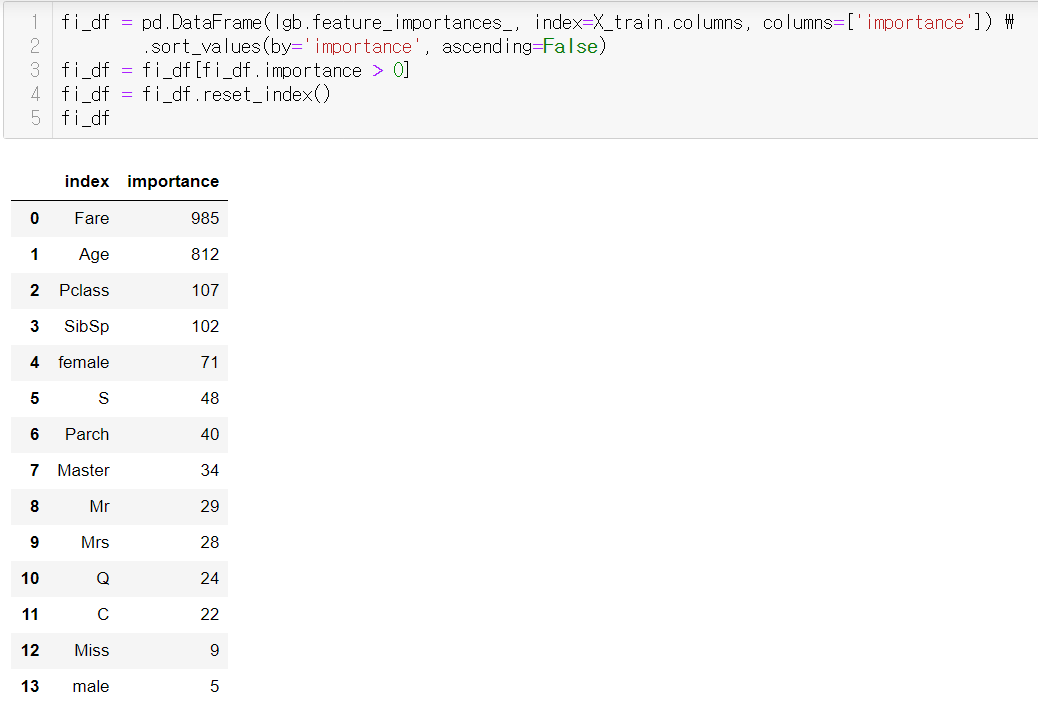

이렇게 따로 feature_importance_를 이용해도 되지만
XGboost와 같이 plot_importance 함수를 쓰면 한번에 그릴 수 있다.

ref
lsjsj92.tistory.com/548?category=853217
반응형
'Machine Learning > 분류(Classification)' 카테고리의 다른 글
| Classification - 모델 평가 : precision_score(정밀도), recall_score(재현율), f1_score (0) | 2020.09.13 |
|---|---|
| Classification - predict_proba (log_loss) (0) | 2020.09.12 |
| Classification - XGBClassifier (0) | 2020.09.09 |
| Classification - RandomForestClassifier (0) | 2020.09.08 |
| Classification - DecisionTreeClassifier (0) | 2020.09.08 |



