반응형
[log_loss]
log_loss는 분류 모델의 손실 함수로 사용되며 Cross Entropy라고도 불림
log_loss는 정확한 label값 (0, 1, ..)을 맞히는 것이 아닌,
모델이 그 클래스를 예측할 확률을 이용해서 평가하는 지표
모델의 fit 이후 predict_proba를 이용하면 각 클래스별 예측 확률을 array형태로 리턴함
현재 학습한 확률이 특정 확률에 대한 참값(목표 확률)에 가까울 수록 cross entropy는 낮아짐
from sklearn.metrics import log_loss
model.fit(X_train, y_train)
y_pred = model.predict_proba(X_valid)
log_loss(y_valid, y_pred)
log_loss는 손실이므로 값이 낮을 수록 잘 예측한 것이다.
https://steadiness-193.tistory.com/257
Machine Learning - valid와 test를 train으로 전처리
https://steadiness-193.tistory.com/256 Machine Learning - train_test_split https://steadiness-193.tistory.com/253 Machine Learning - 랜덤으로 train과 test로 나누기 데이터 불러오기 seaborn의 iris 데..
steadiness-193.tistory.com
위 포스팅에서 만든 데이터셋을 이용하되 LabelEncoder는 꼭 사용해야한다.
Label Encoding

이미 생존, 사망이 1과 0으로 되어있으나
편의를 위해 fit과 transform을 진행한다.
모델은 랜덤포레스트로 진행한다.

predict_proba
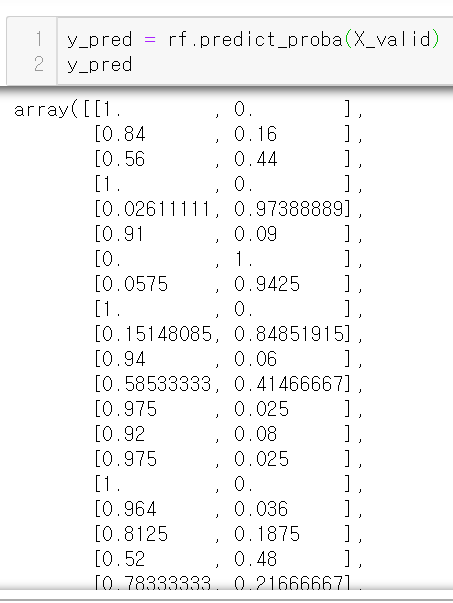
이렇게 predict가 아닌 predict_proba를 하면 승객별 사망, 생존 확률을 따로 구해낼 수 있다.
log_loss

손실 값은 0.56정도가 나왔다.
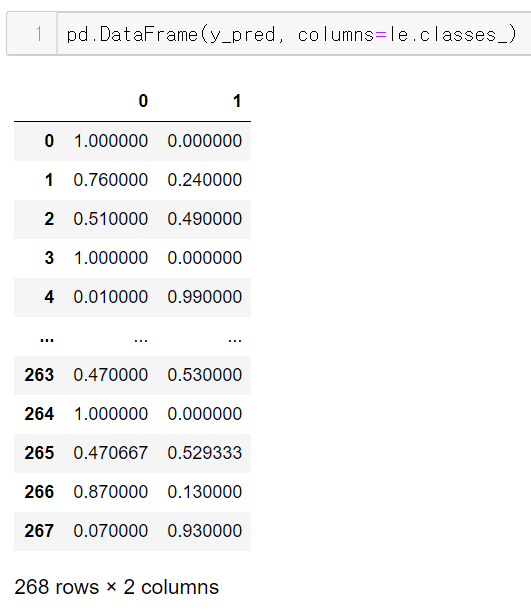
데이터프레임으로 제작

le(LabelEncoder)의 classes_속성에는 label의 순서가 저장되어 있다.
이 순서를 데이터프레임의 컬럼으로 그대로 넣어주면 된다.
참조 :
hyunw.kim/blog/2017/10/26/Cross_Entropy.html
반응형
'Machine Learning > 분류(Classification)' 카테고리의 다른 글
| Classification - 모델 평가 : roc_auc_score (0) | 2020.09.13 |
|---|---|
| Classification - 모델 평가 : precision_score(정밀도), recall_score(재현율), f1_score (0) | 2020.09.13 |
| Classification - LGBMClassifier (0) | 2020.09.10 |
| Classification - XGBClassifier (0) | 2020.09.09 |
| Classification - RandomForestClassifier (0) | 2020.09.08 |



