Permutation Importance
모델 fitting이 끝난 뒤에 측정한다.
Validation의 한 컬럼만 무작위로 섞은 뒤 정확도를 측정한다.
위 작업을 모든 컬럼에 대해서 진행하며
모델이 예측에 크게 의존하는 열을 섞으면 정확도가 크게 떨어지는데, 이를 이용하는 것이다.
위 과정을 완료한 뒤 각 컬럼별 weight의 값과 feature를 리턴해낸다.
Machine Learning - valid와 test를 train으로 전처리
https://steadiness-193.tistory.com/256 Machine Learning - train_test_split https://steadiness-193.tistory.com/253 Machine Learning - 랜덤으로 train과 test로 나누기 데이터 불러오기 seaborn의 iris 데..
steadiness-193.tistory.com
위 포스팅에서 만든 데이터셋을 이용한다.
PermutationImportance 불러온 뒤 학습

eli5 패키지에 있다.
우선 랜덤포레스트로 학습을 한 뒤
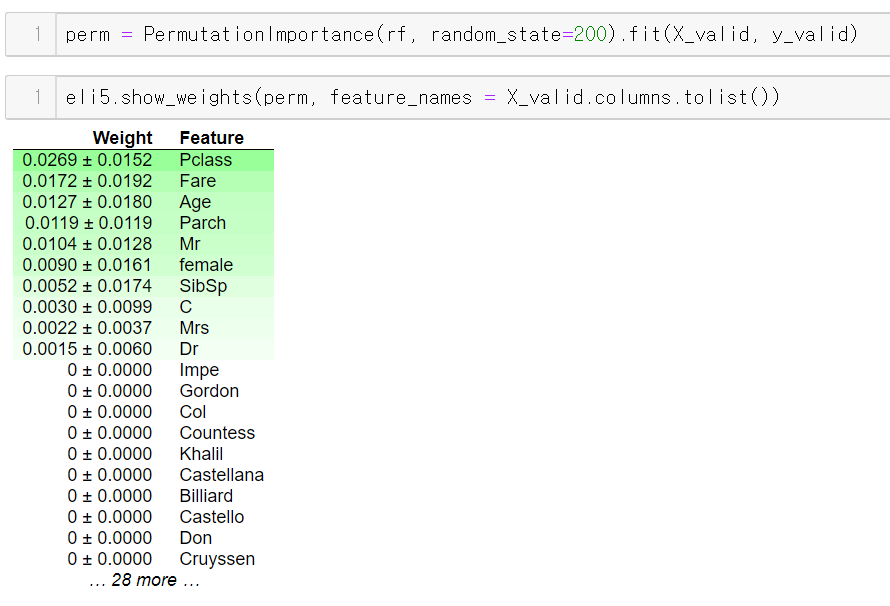
show_weight를 이용하면 중요한 컬럼 순으로 나열해서 보여준다.
(* 주의 : 데이터가 많을 수록 시간이 오래 걸림)
중요한 컬럼 뽑아내기

explain_weights_df로 데이터프레임 형식으로 뽑아낸다.
weight 컬럼에 있는 x숫자는
각 feature의 순서(인덱스)를 나타낸다.
이를 전처리해서 기존 컬럼 배열을 인덱싱 하면

Permutataion importance가 0 초과인 컬럼만 뽑아낼 수 있다.
위 컬럼만 이용해서 예측해보자
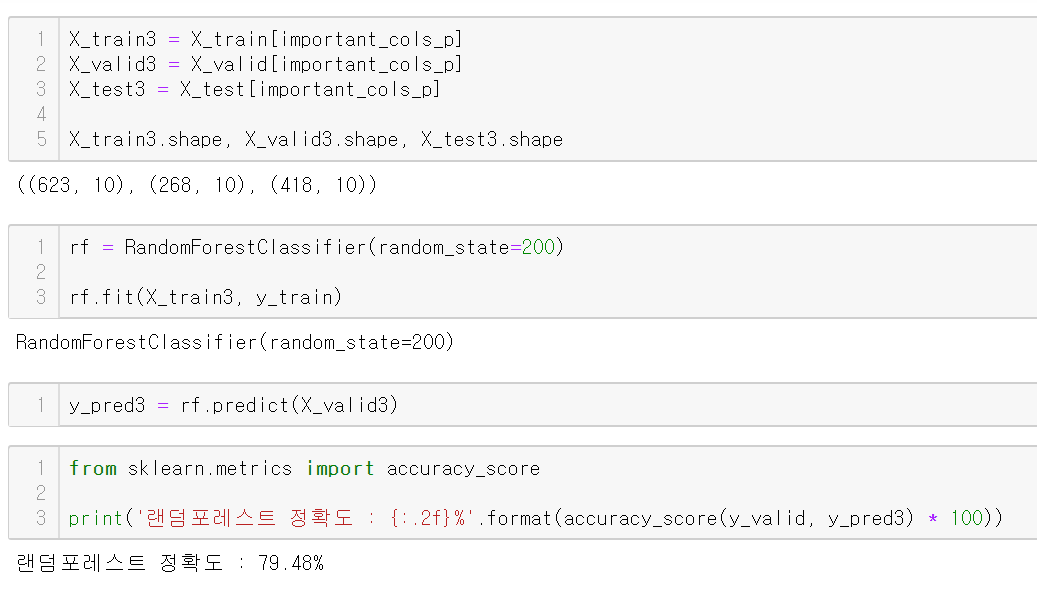
정확도는 약 79.48%가 나왔다.
https://steadiness-193.tistory.com/280
Feature Selection - Feature_importances
https://steadiness-193.tistory.com/261 Classification - RandomForestClassifier https://steadiness-193.tistory.com/257 Machine Learning - valid와 test를 train으로 전처리 https://steadiness-193.tistor..
steadiness-193.tistory.com
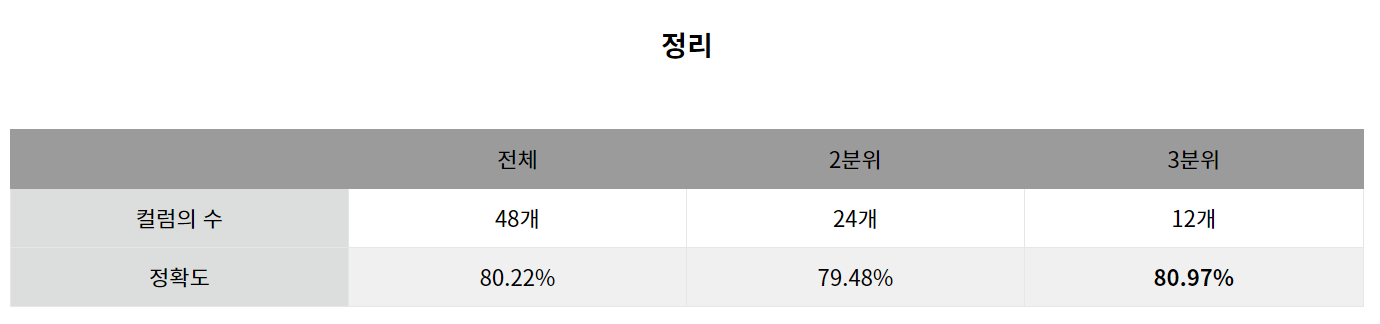
이전 포스팅에서 나온 결과와 비슷한 정확도를 보인다.
이 역시 앙상블 트리 계열이기에 컬럼의 순서에 따라 정확도가 약간씩 차이날 수 있으며
permutation importance가 완벽한 기준이 아님을 인지하고 있어야 한다.
참조
https://eat-toast.tistory.com/10
'Machine Learning > 변수 선택(Feature Selection)' 카테고리의 다른 글
| Feature Selection - Feature_importances + Permutation Importance (0) | 2020.09.16 |
|---|---|
| Feature Selection - Feature_importances (0) | 2020.09.16 |

