https://steadiness-193.tistory.com/280
Feature Selection - Feature_importances
https://steadiness-193.tistory.com/261 Classification - RandomForestClassifier https://steadiness-193.tistory.com/257 Machine Learning - valid와 test를 train으로 전처리 https://steadiness-193.tistor..
steadiness-193.tistory.com
https://steadiness-193.tistory.com/281
Feature Selection - Permutation Importance
Permutation Importance 모델 fitting이 끝난 뒤에 측정한다. Validation의 한 컬럼만 무작위로 섞은 뒤 정확도를 측정한다. 위 작업을 모든 컬럼에 대해서 진행하며 모델이 예측에 크게 의존하는 열을 섞으�
steadiness-193.tistory.com
위 두 포스팅에서 변수를 선택하는 기준을 알아봤다.
그렇다면 두 기준을 이용해서 정확도가 잘 나온 컬럼만 뽑아서 해보면 어떨까?
final columns
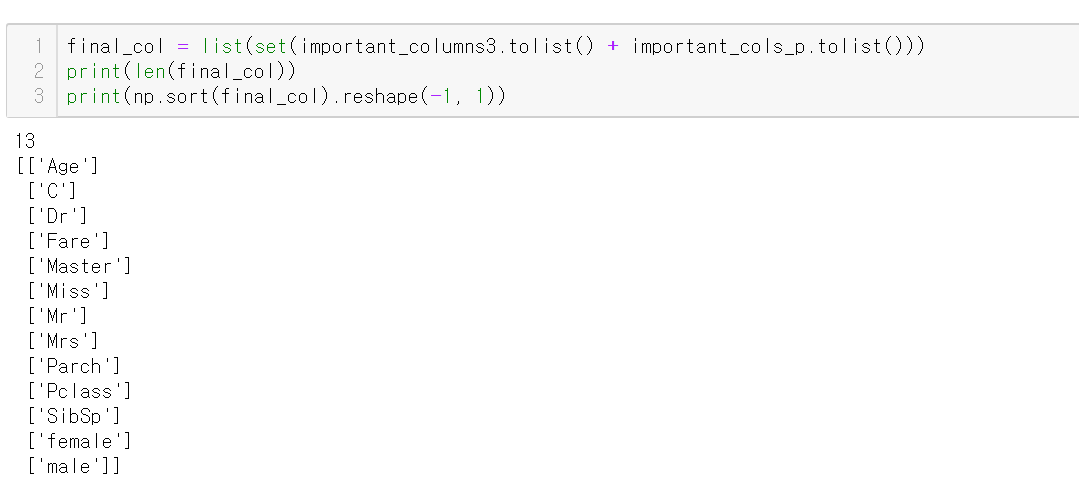
final_col은
feature importances에서 3사분위 값 이상을 가진 12개의 컬럼과
(이 12개 컬럼으로 예측했을 때 정확도가 가장 높았다.)
permutation importance에서 weight를 0 초과로 가진 10개 컬럼을 더해 중복을 제거한 리스트다.
한 가지 빼고는 다 겹쳤다. 즉, 중요한 컬럼은 대개 정해져 있는걸로 보인다.
학습

13개의 컬럼을 이용했다.

정확도는 80.22%가 나왔다.

전체 컬럼을 다 이용한 경우와 같은 정확도(80.22%)를 13개 컬럼으로 구현해 냈다.
다만, 문제가 한가지 있다.
feature importances와 permutation importance를 합친 컬럼 리스트를 만들 때
순서가 매번 바뀌는 것이었다.
그렇게 되면 앙상블 트리 계열의 정확도도 약간씩 차이가 난다.
실제로 여러번 반복해서 실험해본 결과
정확도는 79.85%, 79.48%, 80.22%, 80.60%, 80.97%, 81.34%, 82.09% 이렇게 다양하게 나왔다.
얻은 인사이트
1. 정확도는 약간씩 차이가 날 수 있으나 위 기준으로 변수 선택을 하게 된다면
모든 컬럼을 다 쓰는 것보단 메모리, 시간 대비 효율적이다.
2. 변수 중요도나 permutation importance를 이용해서
실제로 중요하지만 놓쳤거나, EDA에서 발견하지 못했던 중요한 컬럼을 찾을 수도 있다.
3. 저 정도 정확도의 오차는 파라미터 튜닝으로 메울 수 있을 것이다.
'Machine Learning > 변수 선택(Feature Selection)' 카테고리의 다른 글
| Feature Selection - Permutation Importance (0) | 2020.09.16 |
|---|---|
| Feature Selection - Feature_importances (0) | 2020.09.16 |

