https://steadiness-193.tistory.com/286
Validation - KFold
www.kaggle.com/c/titanic/data Titanic: Machine Learning from Disaster Start here! Predict survival on the Titanic and get familiar with ML basics www.kaggle.com 캐글의 타이타닉으로 연습한다. 전처리..
steadiness-193.tistory.com
위 포스팅에서 만든 데이터셋을 이용한다.
Grid Search
클래스 객체에 fit 메서드를 호출하면 grid search를 사용하여 자동으로 복수개의 내부 모형을 생성하고
이를 모두 실행시켜서 최적 파라미터를 찾아준다.
파라미터를 전달하는 매개변수를 딕셔너리 자료형으로 구성한다.
연산 비용이 높으므로 간격을 넓게, 적은 수의 그리드로 시작하는 것이 좋다.
데이터 분리

타이타닉의 data를 train과 valid로 나눠준다.
전처리

전처리 (스케일링, 원핫인코딩 등)을 마친 뒤 46개의 컬럼을 가지고 있다.
* preprocess 함수는 이전 포스팅 참조
GridSearchCV
GridSearchCV 파라미터
estimator, param_grid, scoring=None, n_jobs=None, cv=None, refit=True 등이 있다.
첫번째(estimator)로 평가할 모델을 전달하고
두번째 인자(param_grid)는 각 파라미터와 시험할 값들을 딕셔너리로 넣어준다.
평가 방법은 scoring으로 측정하며 cv는 기본적으로 KFold의 횟수를 정하는 값이다.
https://scikit-learn.org/stable/modules/model_evaluation.html#scoring-parameter
(평가 방식)
refit=True는 생성된 GridSearchCV 객체를, 가장 좋은 파라미터를 전달한 estimator로 바꿔준다.
refit=True옵션으로 바로 predict를 할 수 있다.
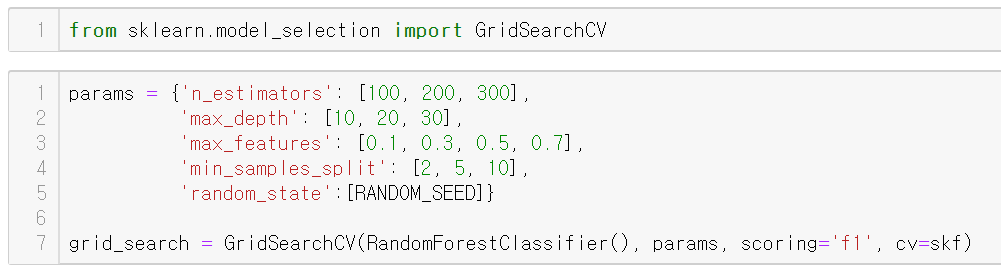
estimator는 RandomForestClassifier를 이용하며
시험해보고 싶은 파라미터는 params에 딕셔너리로 입력했다.
imbalance class이기에 점수 측정은 f1_score를 쓰고 교차검증은 StratifiedKFold를 이용한다.

fit

여러 조합을 실험하고 교차검증도 하기에 약 2-3분 정도 소요됐다.
결과 확인 - 최고 점수

fit을 마친 GridSearchCV객체에 best_score_속성을 이용하면
최고로 높게 나온 점수를 출력받을 수 있다.
결과 확인 - 최고 점수를 예측한 파라미터 조합

위 최고 점수를 만들어낸 최적의 파라미터 값들을 보여준다.
결과 확인 - 그리드 서치의 결과 (딕셔너리)

cv_results_를 이용하면 각 파라미터별 결과를 낸 딕셔너리를 반환하는데,
이를 데이터프레임으로 만든 뒤 rank_test_score 컬럼 기준 오름차순으로 해보았다.
결과 확인 - 최고 점수를 낸 파라미터를 가진 모형
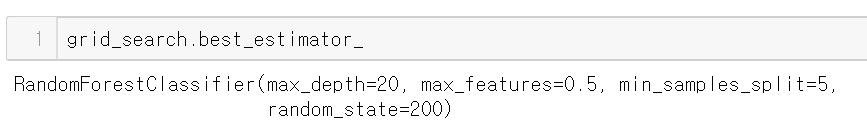
best_estimator_속성으로 최고 점수를 낸 파라미터를 가진 모형을 받을 수 있다.
refit=True 옵션이 디폴트로 들어가 있기 때문에
grid_search 객체는 best_estimator_ 모형이라고 생각해도 된다.
X_valid 예측 및 평가
1. score 이용

위에서 만들어낸 best_estimator_가 X_valid를 예측하고
그 예측한 값을 y_valid와 비교해 f1 score를 낸 것이다.
(scoring='f1' 이므로)
이렇게 score를 이용하면 한번에 예측 성능을 확인할 수 있다.
2. predict

score를 이용하지 않으면 직접 grid_search 객체로 predict를 해야하고
이 예측한 값을 f1_score 함수를 이용해 정답과 비교해 점수를 내야한다.
3. best estimator 추출

best estimator를 다시 rf로 정의해 fit과 predict를 해서 f1 score를 내는 것이다.
위 방법은 굳이 할 필요 없다.
train데이터셋을 교차검증해 나온 최고 점수가 0.72이지만
valid로 평가해본 결과 0.67이 나온 것으로 보아
파라미터를 설정한 모델이 train 데이터에 다소 과적합 되었다고 볼 수도 있다.
참조
datascienceschool.net/view-notebook/ff4b5d491cc34f94aea04baca86fbef8/
scikit-learn.org/stable/modules/model_evaluation.html#scoring-parameter
studychfhd.tistory.com/227
'Machine Learning > 검증(Validation)' 카테고리의 다른 글
| Validation - OOF Ensemble (Out-of-Fold) (2) | 2020.09.23 |
|---|---|
| Validation - Voting Ensemble (VotingClassifier) (0) | 2020.09.22 |
| Validation - StratifiedKFold (Cross Validation) (0) | 2020.09.21 |
| Validation - KFold (0) | 2020.09.21 |



