https://steadiness-193.tistory.com/286
Validation - KFold
www.kaggle.com/c/titanic/data Titanic: Machine Learning from Disaster Start here! Predict survival on the Titanic and get familiar with ML basics www.kaggle.com 캐글의 타이타닉으로 연습한다. 전처리..
steadiness-193.tistory.com
위 포스팅에서 만든 데이터셋과 함수를 이용한다.
필요 라이브러리 호출 및 데이터셋 설정

우선 Voting Ensemble을 하기 전에 그리드 서치를 통해
각 모델별로 최적의 파라미터를 설정한 best estimator를 가져온다.
Validation - GridSearchCV
https://steadiness-193.tistory.com/286 Validation - KFold www.kaggle.com/c/titanic/data Titanic: Machine Learning from Disaster Start here! Predict survival on the Titanic and get familiar with ML b..
steadiness-193.tistory.com
총 3가지 모델 - RandomForest, XGBoost, SVM 을 이용한다.
RandomForest

train으로 찾은 최적의 파라미터로 예측한 값과
정답을 비교한 f1 score는 0.677이 나왔다.
XGBoost
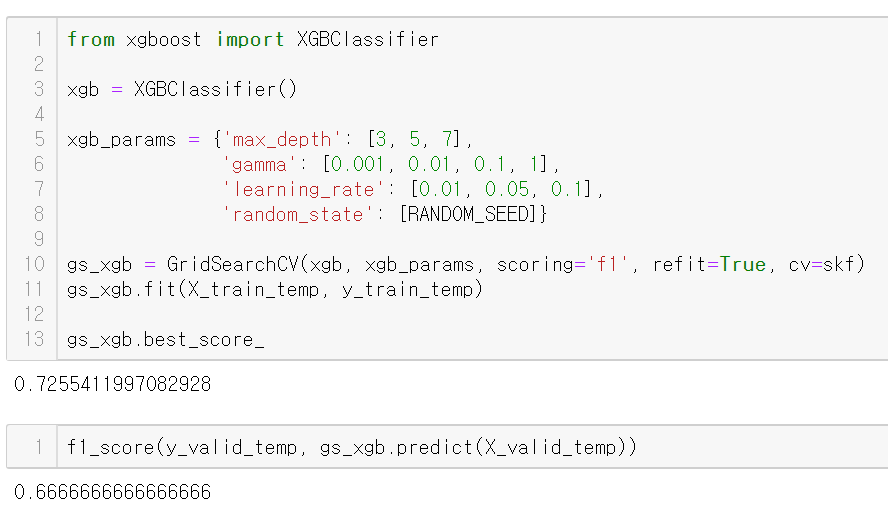
train으로 찾은 최적의 파라미터로 예측한 값과 정답을 비교한
f1 score는 0.666으로 RandomForest보다 낮게 나왔다.
SVM

서포트 벡터 머신이 제일 높은 0.69점을 냈다.
이제 위 세가지 모델끼리 투표를 시켜보자
Voting
서로 다른 알고리즘이 도출해 낸 결과물에 대해, 투표하는 방식을 통해 최종 결과를 선택
Hard Voting (단순 투표)
classifier들의 결과들을 집계하여 가장 많은 표를 얻은 클래스를 최종 예측 값으로 정함

위 그림처럼 3개의 모델이 1이라고 예측하였으므로 앙상블의 예측값은 1이 된다.

VotingClassifier를 불러온 뒤
첫번째 인자인 estimators에 미리 gridsearch로 만들어둔 리스트를 전달한다.
voting은 hard로 설정한다.

fit을 마치고 valid 데이터셋을 예측한 값을 정답과 비교해 측정한 f1 score이다.
랜덤포레스트나 XGBoost를 단독으로 쓰는 것보다는 좋은 성적이다.
Soft Voting (가중치 투표)
각 모델의 예측을 평균 낸 뒤 확률이 가장 높은 클래스를 정답으로 예측

각 모델이 1이라고 예측한 확률은 각각 0.9, 0.8, 0.3, 0.4 이며 이 값들을 산술평균 내면 0.6이다.
반대로 2라고 예측한 확률은 (1 - (1이라고 예측한 확률)) 이며 이를 산술평균 내면 0.4이다.
그러므로 soft voting은 결과를 1로 예측한다.

predict_proba도 해보기 위해 SVC 모델에서 probability=True옵션을 넣어 다시 실행해준다.


보통 hard voting보다 soft voting이 합리적이고 더 범용적으로 쓰인다고 하지만
위 검증에선 정확도가 조금 더 낮게 나왔다.
predict_proba 이용

predict_proba를 이용해 모델이 각 class를 예측한 확률을 받아낼 수 있다.
Classification - predict_proba (log_loss)
[log_loss] log_loss는 분류 모델의 손실 함수로 사용되며 Cross Entropy라고도 불림 log_loss는 정확한 label값 (0, 1, ..)을 맞히는 것이 아닌, 모델이 그 클래스를 예측할 확률을 이용해서 평가하는 지표 모델
steadiness-193.tistory.com
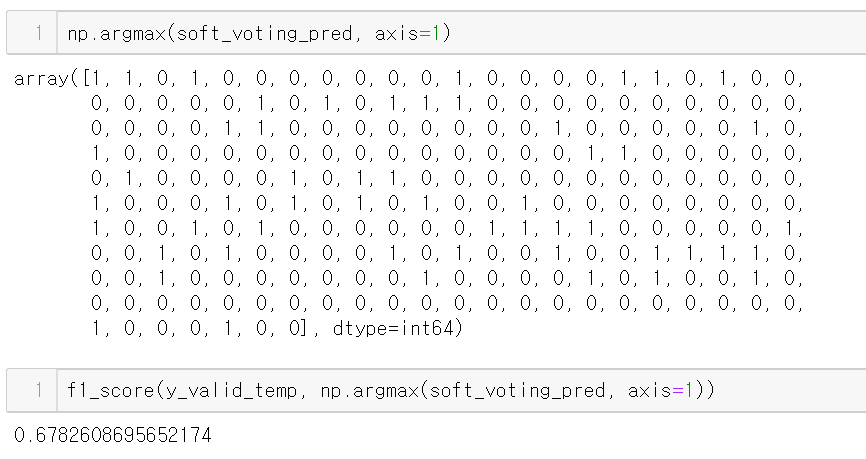
그리고 이렇게 argmax를 이용하면 그냥 predict한 것과 동일한 결과를 얻어낼 수 있다.
참조
teddylee777.github.io/machine-learning/ensemble%EA%B8%B0%EB%B2%95%EC%97%90-%EB%8C%80%ED%95%9C-%EC%9D%B4%ED%95%B4%EC%99%80-%EC%A2%85%EB%A5%98-1
nonmeyet.tistory.com/entry/Python-Voting-Classifiers%EB%8B%A4%EC%88%98%EA%B2%B0-%EB%B6%84%EB%A5%98%EC%9D%98-%EC%A0%95%EC%9D%98%EC%99%80-%EA%B5%AC%ED%98%84
datascienceschool.net/view-notebook/766fe73c5c46424ca65329a9557d0918/
'Machine Learning > 검증(Validation)' 카테고리의 다른 글
| Validation - OOF Ensemble (Out-of-Fold) (2) | 2020.09.23 |
|---|---|
| Validation - GridSearchCV (0) | 2020.09.22 |
| Validation - StratifiedKFold (Cross Validation) (0) | 2020.09.21 |
| Validation - KFold (0) | 2020.09.21 |



