https://steadiness-193.tistory.com/41
판다스 - groupby : transform(응용)
데이터 불러오기 연도별로 그룹화되어있음을 확인했다. 데이터의 평균과 표준편차의 차이인 표준점수를 구하는 함수를 정의한다. 변환된 데이터의 평균값은 0, 표준편차는 1이된다. 데이터가 ��
steadiness-193.tistory.com
이전 포스팅에서 그룹에 따른 결측치를 그룹별 평균으로 채워넣었다.
이번엔 그룹에 따라, 미리 정의된 다른 값을 채워 넣는 경우를 보자
데이터 불러오기


location 별로 그룹화했다.
각 location 별 평균값으로 채워 넣지 않고
그룹별로 정해진 값을 설정한 딕셔너리가 있다면
그 값들로 그룹별 결측치를 채울 수 있다.

각 그룹은 내부적으로 name이라는 속성을 가지고 있다.
이는 동일하진 않지만 딕셔너리의 키 같은 기능을 한다고 보면 된다.
1. apply
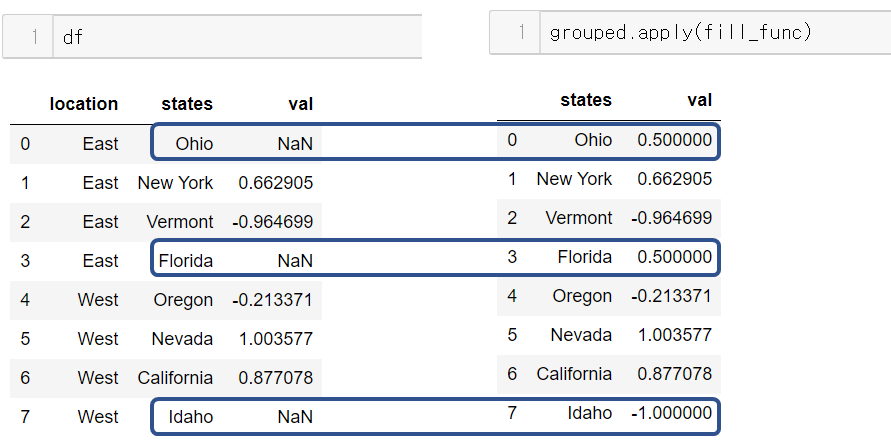
원하는 대로 그룹별로 정해진 값을 채워 넣었다.
2. transform

val 컬럼을 명시해서 transform을 이용하면 하나의 시리즈가 나온다.
이 시리즈를 새로운 컬럼으로 추가하면 된다.
3. 주의할 점
https://steadiness-193.tistory.com/45
판다스 - groupby : apply, filter 등 주의할 점
groupby를 한 객체를 변수에 넣느냐 넣지않고 진행하느냐에 따라 그룹화에 이용된 컬럼이 남아있는가, 사라지는가가 달라진다. 예시를 들어 살펴보자 데이터 불러오기 244행의 tips 데이터를 불러��
steadiness-193.tistory.com
위 포스팅에서와 같이 그룹화된 객체를 변수에 넣고, 안넣고가
중요할 수 있다.

location 컬럼도 봐야한다면
grouped 변수를 이용하지 않는 것이 좋다.
'Pandas > 응용' 카테고리의 다른 글
| 판다스 - pivot_table (피벗 테이블) (0) | 2020.06.25 |
|---|---|
| 판다스 - 멀티인덱스 : loc, xs 인덱서 (0) | 2020.06.24 |
| 판다스 - groupby : 그룹 순회, get_group (0) | 2020.06.24 |
| 판다스 - groupby : apply, filter 등 주의할 점 (0) | 2020.06.23 |
| 판다스 - groupby 메서드들의 활용 방안 (0) | 2020.06.23 |



