https://steadiness-193.tistory.com/85
판다스 - 신생아 이름 (전처리)
데이터 불러오기 신생아 이름에 관련된 데이터는 메모장에 쉼표로 구분되어 있으며 연도별로 파일이 구성되어 있다. 이렇게 2010년까지 있다. 2002년의 메모장을 살펴보면 이름,성별,출생 수 이렇
steadiness-193.tistory.com
위 포스팅에서 만든 names 데이터프레임을 이용한다.

여기서 마지막 글자의 변화가 어떻게 바뀌었는지 알아보자
이를 위해 마지막 글자를 담은 시리즈를 만든다.
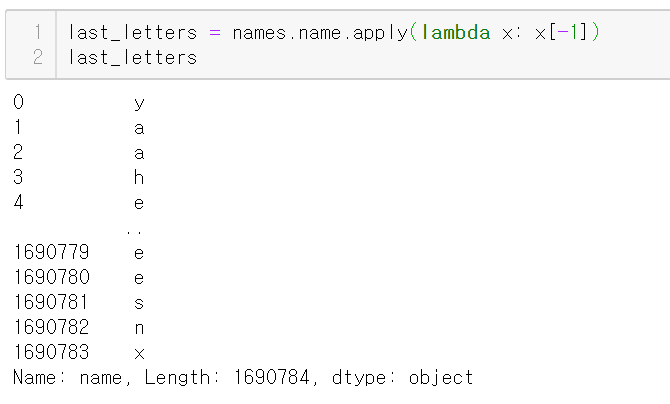
이 시리즈의 name이 기존 컬럼의 name과 겹칠 수 있으니
last_letter로 이름을 바꿔준다.

이제 위 시리즈를 이용해서 피벗테이블을 만들어보자

last_letters 시리즈로 인덱스를 주었고
피벗테이블의 인덱스의 이름은 last_letter로 설정되었다.
위 데이터를 한번에 보기전에
우선 작게 살펴보자

https://steadiness-193.tistory.com/90
판다스 - reindex를 활용한 멀티인덱스 컬럼(열) 추출
https://steadiness-193.tistory.com/89 판다스 - reindex() reindex() 메서드를 사용하면 데이터프레임의 행/열 인덱스를 새로운 배열로 재지정할 수 있다. 기존 객체를 변경하지 않고 새로운 데이터프레임 객체
steadiness-193.tistory.com
reindex에 대한 내용은 위 포스팅 참조
우선
1910년 1960년 2010년을 기준으로 subtable을 만들었다.
다만 이 값들이 절대적으로 차이가 나기때문에
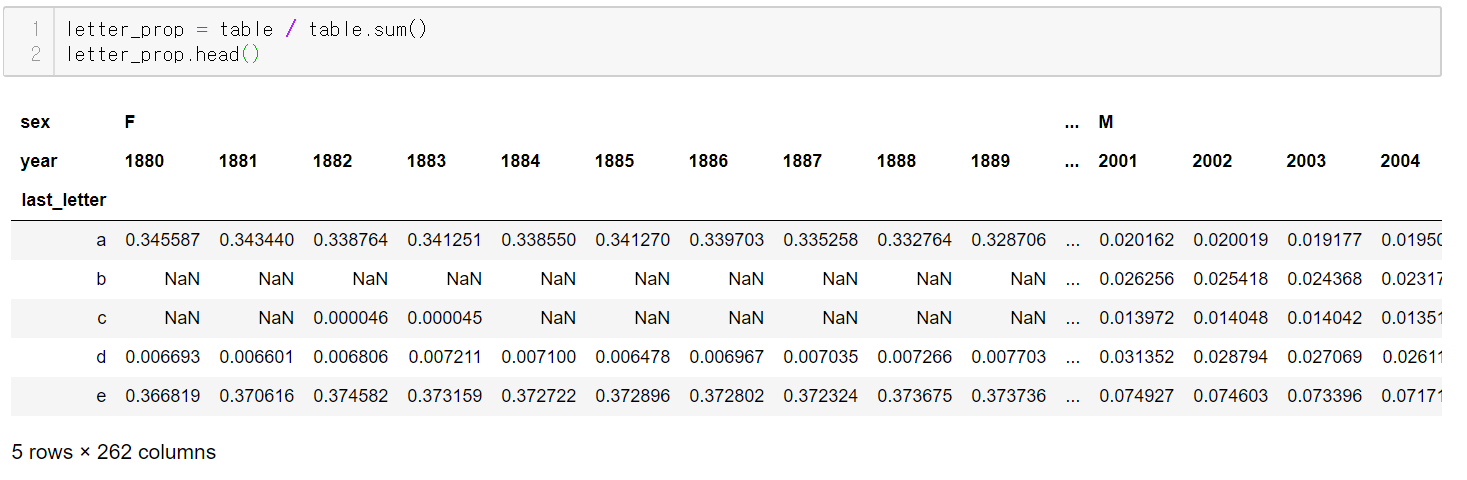
정규화를 진행한다.

성별/ 연도별 합한 값으로 개별 값을 나누면 정규화된 값을 얻을 수 있다.

이제 이 letter_prop을 그래프로 시각화해보자
남아 기준

d, n, y 알파벳이 빈도의 변화가 있어보이니
이 세 알파벳을 따로 추출하여 분석해보자
이제 1910년 1960년 2010년이 아닌
전체 테이블로 보면

위 테이블이 나온다.
여기서 남아의 d, n, y만 뽑으면

위와 같이 나온다.
다만 컬럼이 아닌 인덱스에 연도가 있으면 편하니 행/열의 위치를 바꾸는
transpose() 또는 T를 이용한다.

이제 이 그래프를 시각화하면

예상대로 시간이 지날 수록 마지막 글자의 변화가 있는 것을 볼 수 있다.
여아 기준

1910, 1960, 2010년을 기준으로 봤을 때 a, e, n이 마지막 글자로서 변화가 많았다.
이제 똑같이 전체 테이블을 정규화 한 뒤
여아의 a, e, n 행만 가져온다.

이를 전치 메서드를 이용해 바꿔주고

그래프를 그려보자

알파벳 e의 사용 빈도가 확실히 줄어든 것을 볼 수 있다.
'Pandas > 실전' 카테고리의 다른 글
| 판다스 - 미국농무부 영양소 정보 (json 데이터 전처리) (0) | 2020.07.08 |
|---|---|
| 판다스 - 미국 신생아 이름 : 이름의 성별 변화 (0) | 2020.07.05 |
| 판다스 - 미국 신생아 이름2 : 유행 분석, 이름 사용 경향 (0) | 2020.07.03 |
| 판다스 - 미국 신생아 이름 : 전처리 (0) | 2020.07.02 |
| 판다스 - 시간 범위 수정하고 데이터 밀어내기 : date_range, first_valid_index, shift (0) | 2020.07.01 |



