https://steadiness-193.tistory.com/85
판다스 - 신생아 이름 (전처리)
데이터 불러오기 신생아 이름에 관련된 데이터는 메모장에 쉼표로 구분되어 있으며 연도별로 파일이 구성되어 있다. 이렇게 2010년까지 있다. 2002년의 메모장을 살펴보면 이름,성별,출생 수 이렇
steadiness-193.tistory.com
위 포스팅 끝부분에 얻어낸 top1000 데이터프레임을 이용한다.

예전에는 남자 이름으로 선호되던 이름이 시간이 지날수록 여자 이름으로 사용되는 경우를 보자
대표적으로 Lesley, Leslie라는 이름이 그렇다.
우선 lesl로 시작하는 이름을 포함하는 목록을 만들어야 한다.

대소문자 구별을 피하기 위해 우선 lower함수를 적용하고
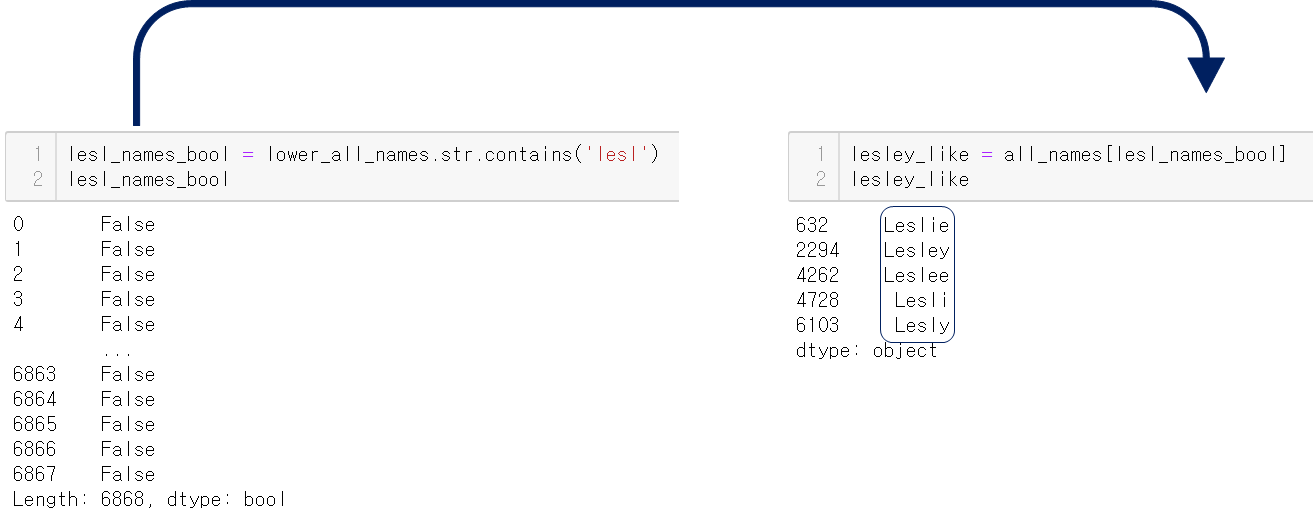
str.contains()를 이용해 lesl 불린 시리즈를 만들어
이를 all_names에 필터 조건으로 이용한다.
그럼 찾고있던 lesl로 시작하는 이름을 다 찾아냈다.
그러면 이제 이 lesl_like를 가지고
top1000전체 데이터프레임을 필터링해보자
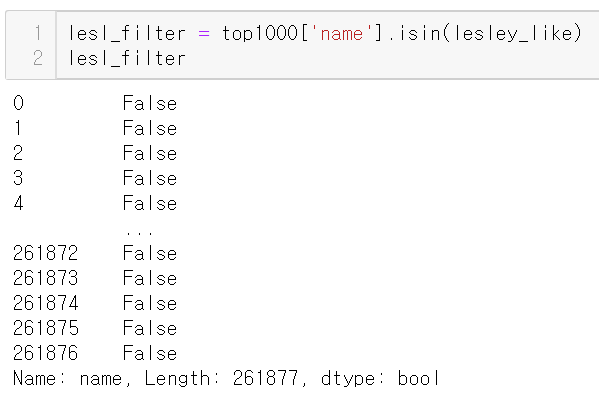
top1000의 name 컬럼에서 lesl 필터를 적용해
top1000 와 동일한 크기의 불린 시리즈를 만들어 냈고
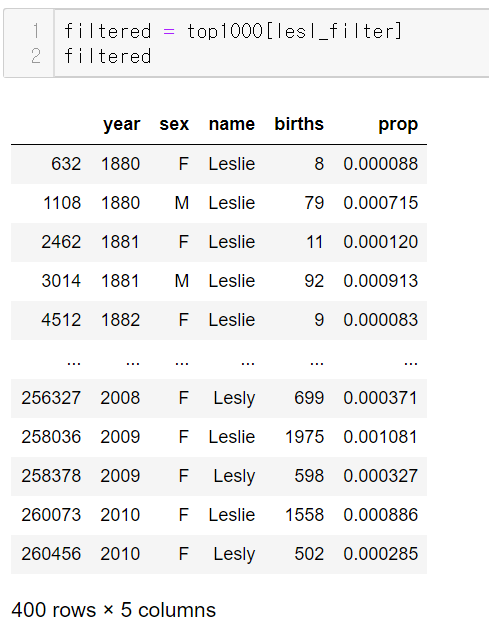
이를 다시 top1000 데이터프레임 필터에 이용하니
총 400개의 행만 남았다.
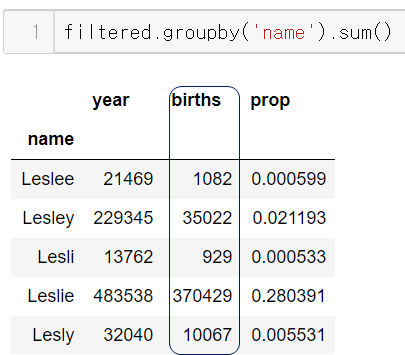
groupby로 이름을 묶어보니
압도적으로 Leslie 철자의 이름이 많이 지어졌다.
이렇게 groupby를 해보니 절대적인 값의 차이가 큰 것을 확인했다.
즉, 비교를 위해선 정규화를 진행해야한다는 것이다.
다시 filtered 데이터프레임으로 돌아가서 피벗테이블을 만들어보자
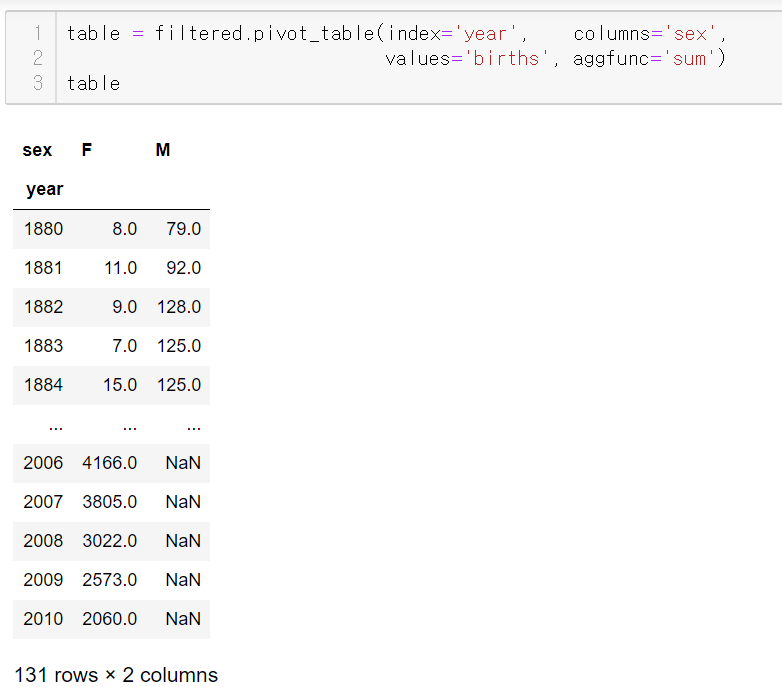
이를 바로 그래프로 그리면 정규화가 되지 않아 그래프의 차이가 크게 나온다.

따라서
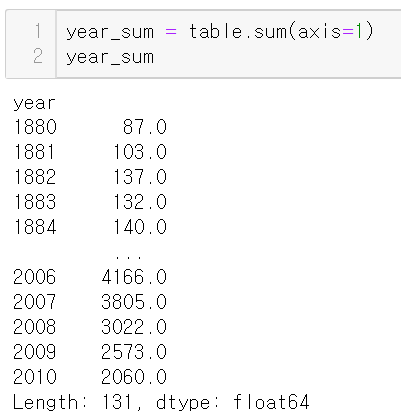
연도별 출생 수의 합으로
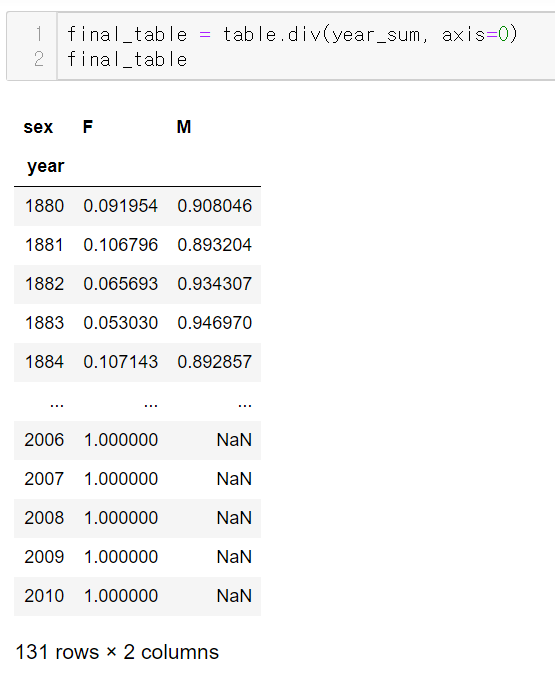
기존 피벗테이블을 연도별로 나눠준다.

이제 final_table로 시각화 해보면
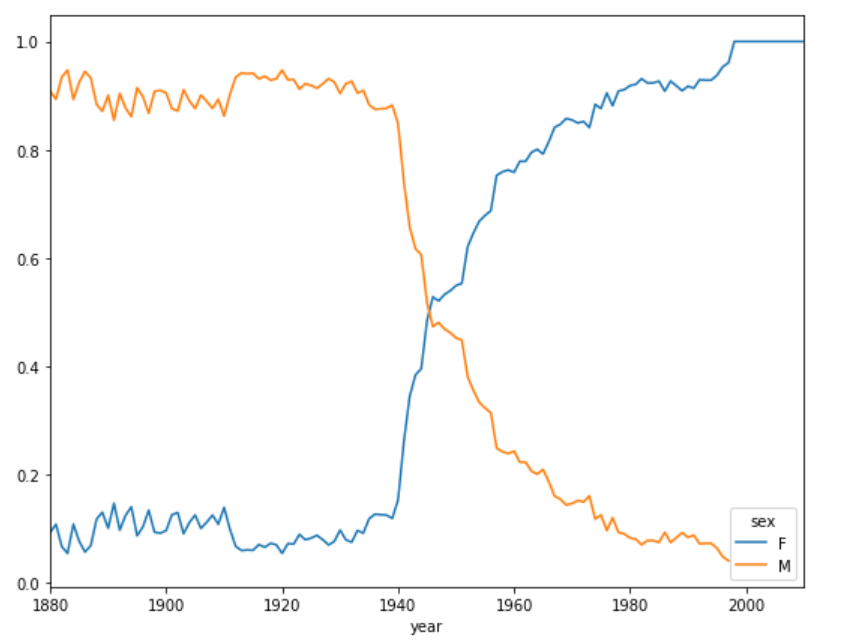
lesl로 시작하는 이름의 비율이
원래는 남자에서 높다가 시간이 흐를수록 여자에서 높아지는 것을 볼 수 있다.
'Pandas > 실전' 카테고리의 다른 글
| 판다스 - 미국농무부 영양소 정보 (json 데이터 전처리2) (0) | 2020.07.08 |
|---|---|
| 판다스 - 미국농무부 영양소 정보 (json 데이터 전처리) (0) | 2020.07.08 |
| 판다스 - 미국 신생아 이름 : 마지막 글자의 변화 (0) | 2020.07.04 |
| 판다스 - 미국 신생아 이름2 : 유행 분석, 이름 사용 경향 (0) | 2020.07.03 |
| 판다스 - 미국 신생아 이름 : 전처리 (0) | 2020.07.02 |



