반응형
https://steadiness-193.tistory.com/75
판다스 - groupby : 함수로 그룹핑하기
사전이나 시리즈로 그룹핑하는 것보다 함수로 그룹핑하는 것이 보다 더 일반적이다. 그룹 색인으로 넘긴 함수는 색인값 하나마다 한 번씩 호출되며 반환값은 그 그룹의 이름으로 사용된다. 데��
steadiness-193.tistory.com
위 포스팅과 내용의 맥은 같다.
인덱스를 함수로 그룹핑
그룹 색인으로 넘긴 함수는 색인값 하나마다 한 번씩 호출되며
반환값은 그 그룹의 이름으로 사용된다.
데이터 불러오기
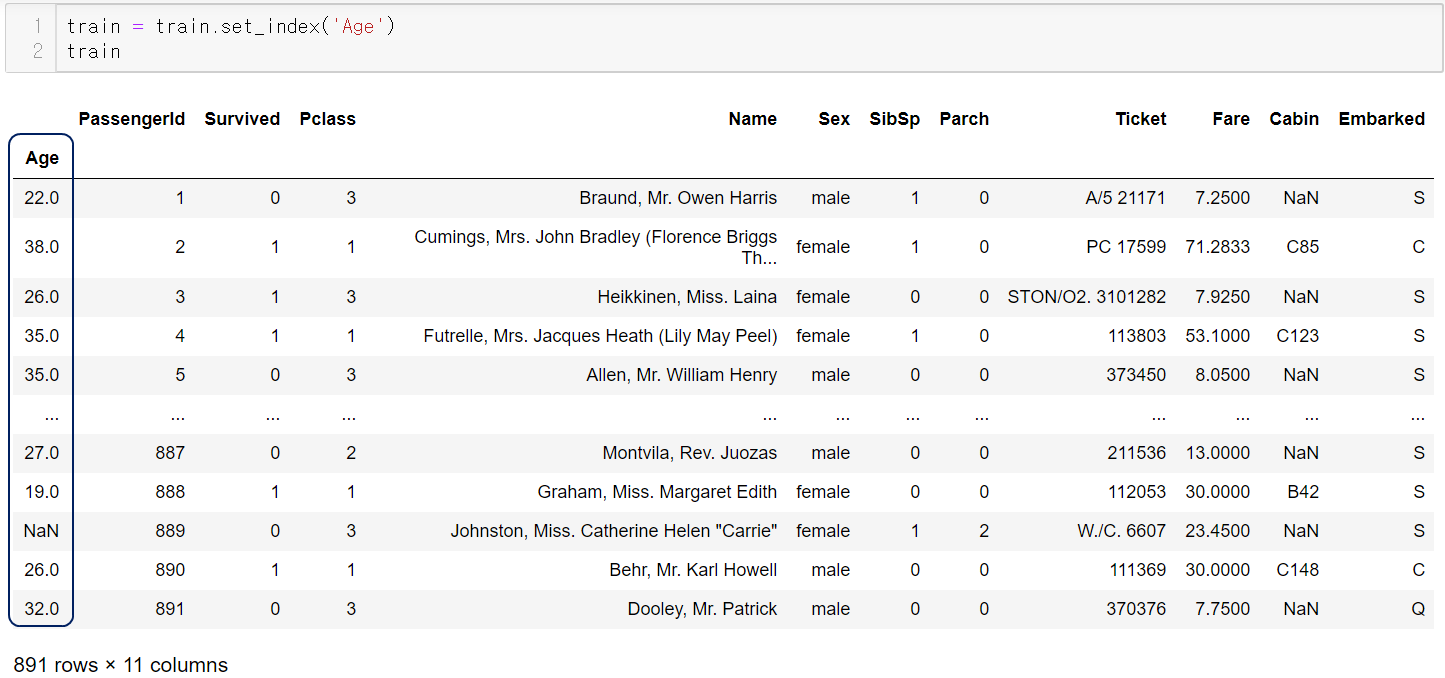
물론 이렇게 인덱스를 설정할리가 거의 없겠으나
설명의 목적으로
나이를 인덱스로 설정했다.

심지어 인덱스에 NaN도 있다.
[목표 : 나이대 별로 생존율의 평균 파악]
함수 정의

age의 값이 nan이라면 -1을 반환하고
아니라면 나이대를 반환한다.
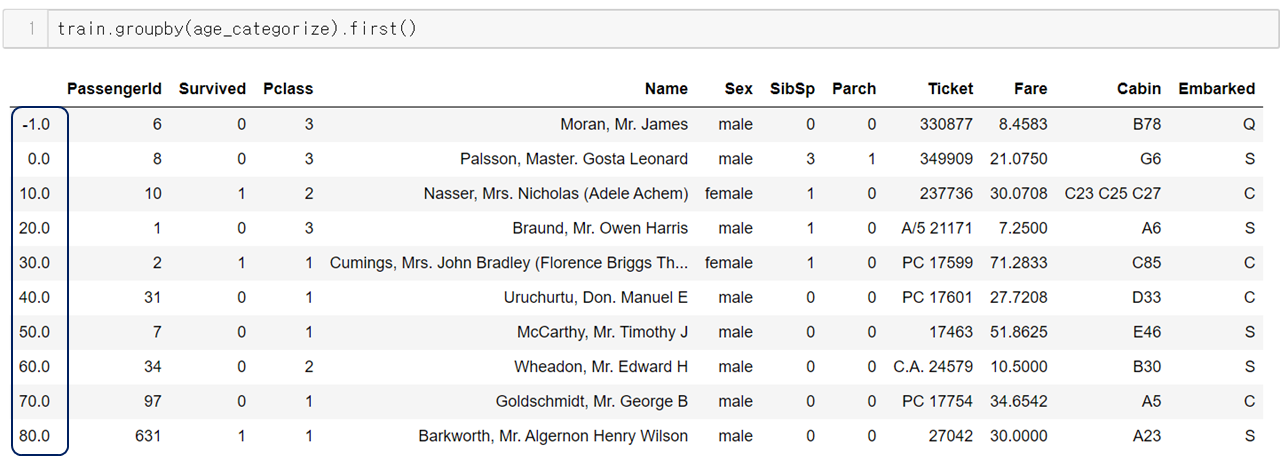
위 함수를 groupby에 바로 전달하면
자동으로 인덱스에 apply처럼 적용된다.

size()를 이용해 각 그룹별 행의 개수를 파악할 수도 있다.

우리가 목표로 했던 나이대별 생존율이 나왔다.
1명이었던 80대를 제외하면
10세 미만의 생존율이 가장 높았으며 그 다음으로는 30대, 50대 순이다.
사실 위 과정은 set_index를 이용해서도 동일하게 나타낼 수 있다.
데이터 불러오기
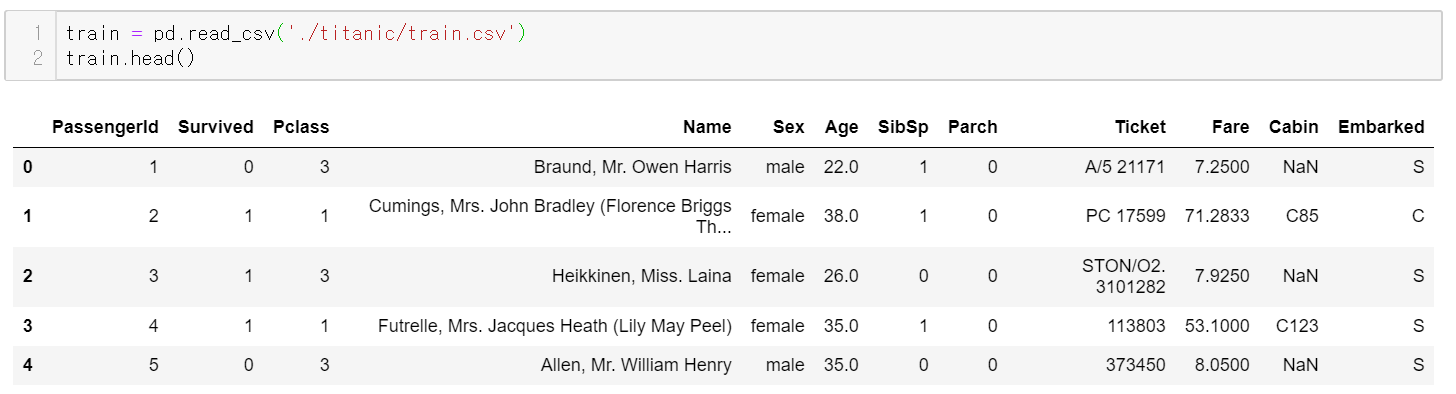
인덱스는 기본 인덱스이다.
set_index & groupby
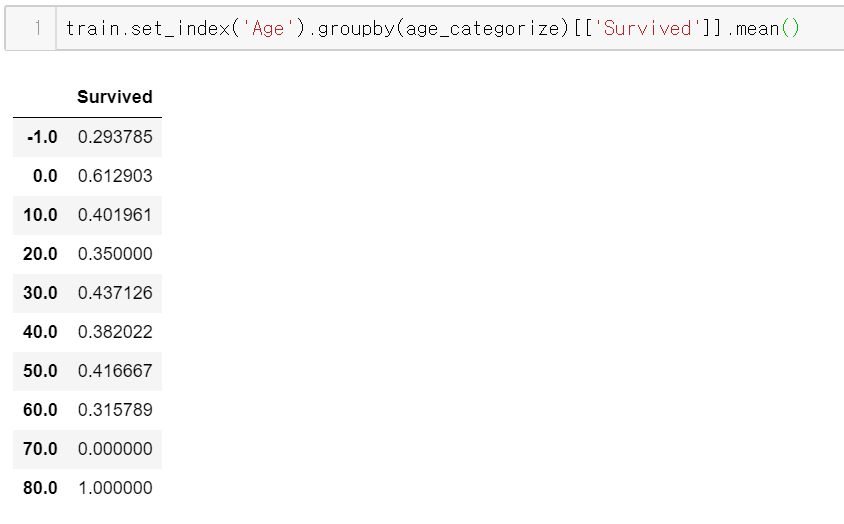
굳이 인덱스를 바꿔가면서 할 필요 없이
set_index를 통해 원본 변경 과정 없이 원하는 결과를 간단히 볼 수 있다.
반응형
'Pandas > 응용' 카테고리의 다른 글
| 판다스 - groupby : 멀티인덱스, idxmax 활용 (0) | 2020.07.08 |
|---|---|
| 판다스 - 콤마(,) 로 구분된 컬럼에서 원하는 데이터 추출하기 (0) | 2020.07.08 |
| 판다스 - groupby : 인덱스로 그룹화하기 (멀티인덱스, level) (0) | 2020.07.07 |
| 판다스 - 누락데이터를 그룹별로 대체하여 컬럼(열) 만들기 : insert, groupby, transform, fillna (0) | 2020.07.06 |
| 판다스 - 원하는 위치에 조건에 맞는 컬럼(열) 추가 : insert 응용 (0) | 2020.07.06 |



