데이터 출처
https://www.kaggle.com/shivamb/netflix-shows#netflix_titles_nov_2019.csv
Netflix Movies and TV Shows
Movies and TV Shows listings on Netflix
www.kaggle.com
데이터 살펴보기

위 데이터프레임에서 0번째 행의 country를 보면
미국, 인도, 한국, 중국이 같이 적혀 있다.

따라서 이렇게 South Korea 랑 같냐는 코드는 당연히
False가 나온다.

오로지 South Korea만 적혀있는 행은 총 136개다.
[목표 : 한국이 입력되어있는 모든 행의 개수 찾기]

우선 , 로 구분되어 있기 때문에
split을 이용해 각 단어를 잘라 리스트로 만든다.
* 주의 : ,와 공백을 합친 것으로 split 해야함

str.split을 이용해서 모든 행을 다 리스트화 한다.
https://steadiness-193.tistory.com/22
판다스 - 컬럼(열) 분리, 컬럼(열) 추가 : str.split, str.get
데이터 불러오기 연월일 컬럼을 연 / 월 / 일 세개의 컬럼으로 나눠서 보고 싶다면 방법1 : str.split() 1. 연월일 컬럼의 자료형을 object로 변환한다. 2. 판다스의 자료형과 파이썬의 문자열을 이용해
steadiness-193.tistory.com
위 포스팅 참조
그렇게 만든 시리즈를 원하는 위치에 컬럼으로 추가한다.
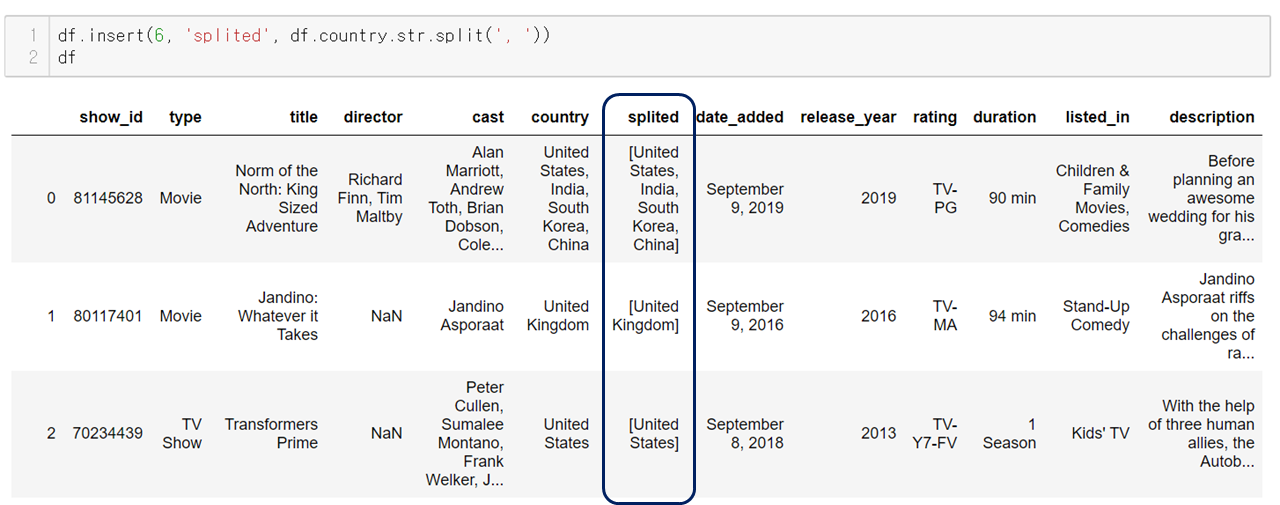
이후 작업 전에
country 컬럼에서 누락값이 있는 행의 개수는

총 476개다.
이는 어차피 알기 어려우므로 삭제해주자

기존 6234행에서 476행을 뺀 5758행만 남았다.
apply를 이용할 함수를 정의한다.

South Korea가 들어가면 n_list에 True를 넣고
True가 있는 행(리스트)이라면 합이 1 이상일 것이므로
최종적으로 True를 반환하게 한다.

0번째 행에는 분명 한국이 있어,
True가 나왔다.

한국이 들어간 행의 개수가 162개로 늘어났다.
이제 apply한 시리즈를 필터 조건으로 넣고
한국이 들어간 행만 추출하자
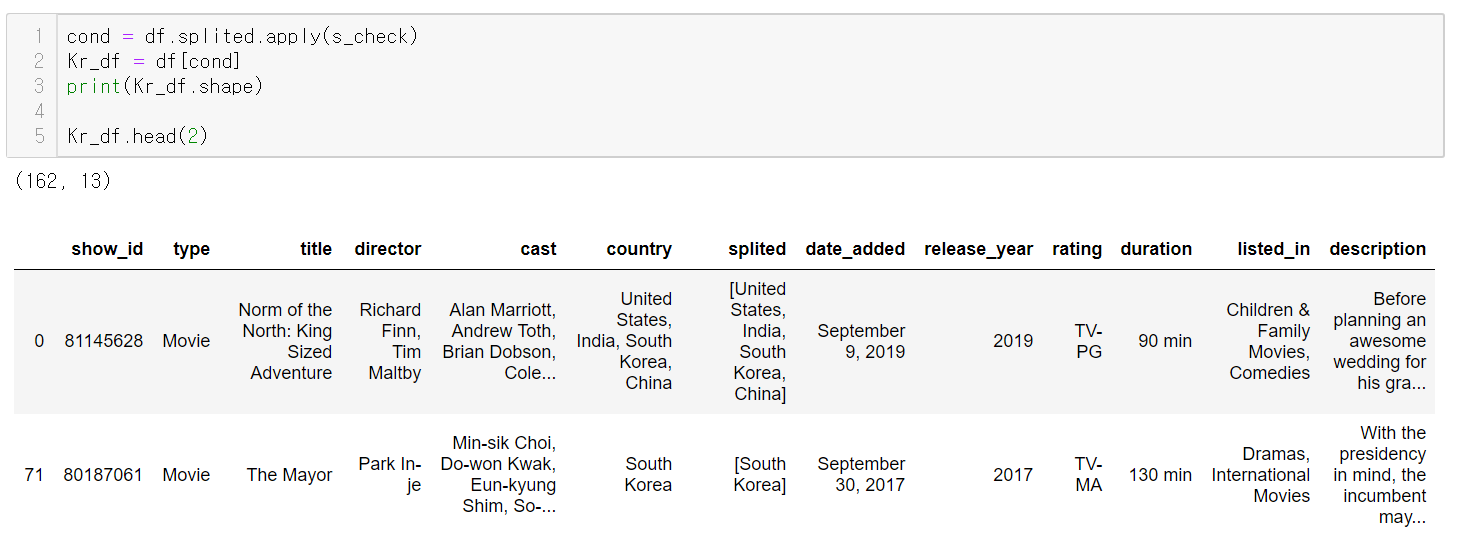
162행으로 데이터프레임이 잘 나왔다.
이를 groupby를 활용해 분석할 수도 있다.
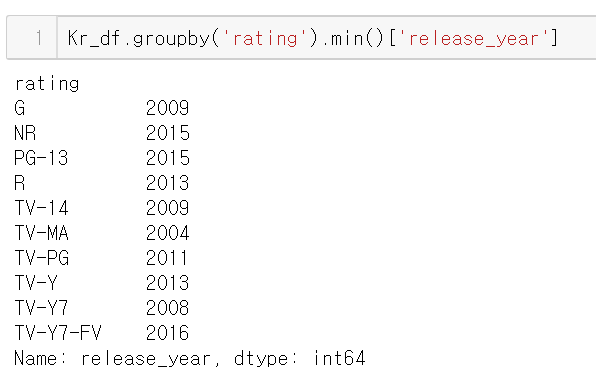
한국이 제작 or 제작에 관여한 콘텐츠의
연령 등급별 최초 개봉 연도
'Pandas > 응용' 카테고리의 다른 글
| 판다스 - groupby : 컬럼 선택 (SeriesGroupBy, DataFrameGroupBy) (0) | 2020.07.12 |
|---|---|
| 판다스 - groupby : 멀티인덱스, idxmax 활용 (0) | 2020.07.08 |
| 판다스 - groupby : 인덱스를 함수로 그룹핑하기 (0) | 2020.07.07 |
| 판다스 - groupby : 인덱스로 그룹화하기 (멀티인덱스, level) (0) | 2020.07.07 |
| 판다스 - 누락데이터를 그룹별로 대체하여 컬럼(열) 만들기 : insert, groupby, transform, fillna (0) | 2020.07.06 |



