데이터 불러오기

타이타닉의 train 데이터셋을 받아왔다.
https://steadiness-193.tistory.com/14
판다스 - 누락 데이터 확인(isnull(), count_nonzero())
타이타닉 데이터 불러오기 deck 컬럼의 경우 전체 891개의 행 중 203개의 행만 값이 채워진 것을 볼 수 있다. value_counts()로 누락값 개수 확인하기 누락데이터의 개수를 확인하고자 하면 value_counts에
steadiness-193.tistory.com
위 포스팅 내용을 이용해
각 컬럼별 누락값을 살펴보면

총 3컬럼에서 누락값이 있는 것을 확인할 수 있다.
그 중 Age 컬럼을 채우는 방법을 살펴보자
사실 그냥 Age컬럼의 평균값으로 누락값을 채워도 되지만

이는 위험할 수도 있다.
그 이유는 다른 컬럼과의 관계가 있을 수 있기 때문이다.
다시 예를 들면
Survived 컬럼과 성별 컬럼의 값에 따라 나이의 평균값이 다를 수도 있다는 것이다.
우선 Survived는 0과 1로 이루어진 값인데 각 값의 개수는

비율이 딱 절반도 아니며
성별 또한
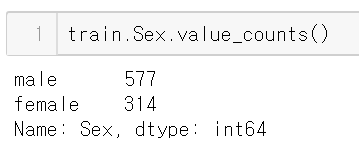
남자가 더 많다.
따라서
Survived와 성별에 따라 그룹화하고 그 그룹별로 평균값을 찾아야 한다.
이를 위해 groupby를 활용한다.

그냥 Age 컬럼의 평균과 비교해보면

살아남지 못한 남자의 나이 평균은 31세로 전체 평균보다 2가 높다.
이렇게 그룹별로 다르니 이를 활용해 누락값을 대체해야 한다.
https://steadiness-193.tistory.com/15
판다스 - 누락 데이터 처리 (dropna, thresh, fillna, idxmax, ffill, bfill)
데이터 불러오기 dropna, thresh 불린 조건을 '입력된 값의 개수가 전체 행의 개수와 같지 않다'로 설정 즉, age, embarked, deck, embark_town은 누락값이 있다. 시리즈에 cond로 필터링하면 누락값이 있는..
steadiness-193.tistory.com
https://steadiness-193.tistory.com/41
판다스 - groupby : transform(응용)
데이터 불러오기 연도별로 그룹화되어있음을 확인했다. 데이터의 평균과 표준편차의 차이인 표준점수를 구하는 함수를 정의한다. 변환된 데이터의 평균값은 0, 표준편차는 1이된다. 데이터가 ��
steadiness-193.tistory.com
위 두 포스팅 내용을 이용해서

Age 컬럼의 누락값을
Survived와 성별에 따라 나이의 평균값으로 대체한 시리즈를 만들어 낸다.
https://steadiness-193.tistory.com/94
판다스 - 원하는 위치에 컬럼 추가 (insert)
데이터프레임.insert(원하는 컬럼의 위치, 새롭게 들어갈 컬럼의 이름, 조건) - 컬럼의 위치는 0부터 시작 - 조건을 변수에 넣어서도 이용 가능 데이터 불러오기 [목표 : weight 컬럼 옆에 weight 컬럼을
steadiness-193.tistory.com
이제 insert를 이용해 비교가 용이하도록
Age 컬럼 옆에 바로 age_filled 시리즈를 컬럼으로 추가하자

잘 채워졌는지 확인을 위해
기존 Age 값이 빈 행만 보자

Survived와 성별에 따라 누락값이 잘 채워졌다.
'Pandas > 응용' 카테고리의 다른 글
| 판다스 - groupby : 인덱스를 함수로 그룹핑하기 (0) | 2020.07.07 |
|---|---|
| 판다스 - groupby : 인덱스로 그룹화하기 (멀티인덱스, level) (0) | 2020.07.07 |
| 판다스 - 원하는 위치에 조건에 맞는 컬럼(열) 추가 : insert 응용 (0) | 2020.07.06 |
| 판다스 - 여러 대용량 데이터 처리하기 : os.listdir (0) | 2020.07.06 |
| 판다스 - reindex를 활용한 멀티인덱스 컬럼(열) 추출 (0) | 2020.07.04 |



