| INPUT | USE | RETURN |
| 시리즈 원소 | apply | 단일 값, 시리즈 |
| 시리즈 객체 (데이터프레임의 행 or 열) | 단일 값, 시리즈, 데이터프레임(통합) | |
| 데이터프레임의 원소 | applymap | (동일한 형태의)데이터프레임 |
| 데이터프레임 객체 | pipe | 단일 값, 시리즈, 데이터프레임 |
데이터 불러오기

데이터 살펴보기

총 891행, 15열
컬럼의 자료형도 확인할 수 있다.
이전 응용1 글에선 apply와 pipe의 결과가 동일한 함수를 보았다.
이번엔 조금 다른 함수를 보자.
이전 함수를 이용하기에 이전 함수에 대한 코드와 결과를 첨부한다.



함수 생성 및 결과 확인

size 속성은 시리즈의 행 개수를 셀 때 이용한다.
데이터프레임에 이용하면 모든 데이터의 수를 센다.
(행 x 열)
이제 하나씩 뜯어보자
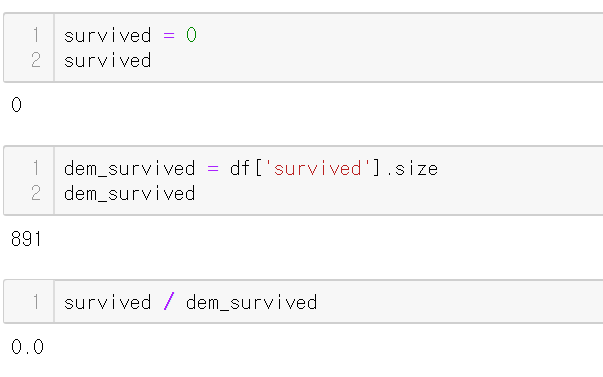
apply는 하나의 컬럼, 즉 시리즈를 받는다.
이전 함수에서 survived의 결과는 0 이었다.
survived의 size를 구하기 위해
dem_survived의 변수를 이용해 구했다.
당연히 행의 개수가 나오며 이는 891로 리턴되었다.
0 나누기 891은 0이다.
그렇다면 0 이아닌 age컬럼을 보면 어떨까?

이전 함수에서 age컬럼의 빈 값은 177개였다.
age컬럼의 행의 개수는 여전히 891개다.
177 나누기 891은 0.1986으로 나온다.
이 처럼 한 컬럼씩 값이 나오고
이 값들을 연결해 시리즈로 나타낸 것이 apply다.
아래는 최종 결과다.

count_missing 처럼 pipe도 결과가 같을까?
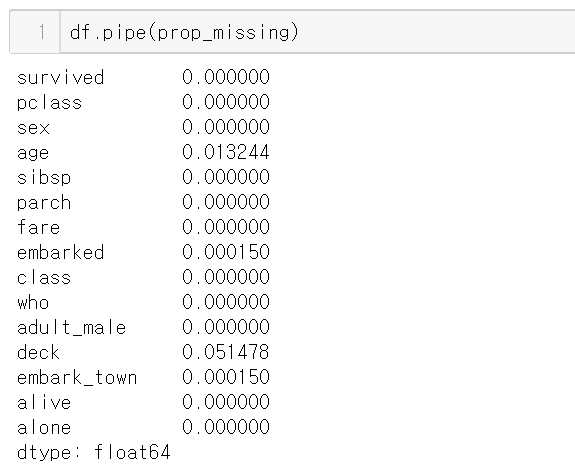
같지 않다.
하나씩 뜯어보자.

함수에서 바뀐 것은 d_frame의 파라미터 뿐이다.
여기서 다른 것은 pipe는 데이터프레임 객체를 받는다는 것이다.
즉 df.size를 하면 한 컬럼의 행의 개수가 아니라
행 * 열의 값이 나온다.
891 * 15 = 13365이다.

sum_까지는 apply와 결과가 비슷하지만
시리즈(sum_)와 스칼라(13365)의 연산을 한 브로드캐스팅의 결과는 다음과 같다.

apply일땐 행별로 값을 891로 나눴지만
지금은 13365로 나눈다.
그래서 결과가 달라진 것이다.

이처럼 apply와 pipe는 리턴의 형태가 같을 순 있지만
pipe는 데이터프레임의 객체를 받으므로 유의해서 사용해야할 것이다.
* 참고 : 두 함수 모두 applymap을 이용하면 오류 발생
(데이터프레임을 리턴해야 하므로)
'Pandas > 응용' 카테고리의 다른 글
| 판다스 - groupby (0) | 2020.06.22 |
|---|---|
| 판다스 - apply, applymap, pipe(응용3) (0) | 2020.06.22 |
| 판다스 - apply, applymap, pipe(응용1) (0) | 2020.06.21 |
| 판다스 - apply, applymap, pipe(2) (0) | 2020.06.20 |
| 판다스 - apply, applymap, pipe(1) (2) | 2020.06.20 |



