반응형
데이터 불러오기

C컬럼의 초성을 기준으로 그룹화하고자 한다.
이때 이용하는 메서드가 바로 groupby 이다.

다른 것과 달리 그냥 grouped를 보고자하면 나오지 않는다.
집계 메서드를 사용해야 그룹화된 데이터프레임을 볼 수 있다.
groupby - 집계 메서드
|
count |
누락값을 제외한 데이터 수 |
|
size |
누락값을 포함한 데이터 수 |
|
데이터프레임 -> .size() / 시리즈 -> .size |
|
|
위 사항을 잘 구분해서 사용해야 한다. |
|
|
mean |
평균값 |
|
min |
최솟값 |
|
max |
최대값 |
|
sum |
전체 합 |
|
describe |
데이터 수, 평균, 표준편차, 최솟값, 최대값, 백분위수 |
|
quantile(q=0.25) |
백분위수 25% |
|
quantile(q=0.50) |
백분위수 50% |
|
quantile(q=0.75) |
백분위수 75% |
|
first |
첫번째 행 |
|
last |
마지막 행 |
|
nth |
n번째 행 |

필자는 어떤 그룹으로 되어있는지 first를 이용해 한번 살펴본다.
'C컬럼의 ㄱ, ㄴ, ㄷ으로 그룹화되었구나' 라고 판단할 수 있다.
count / size

그룹화된 데이터프레임에 count를 사용하면
컬럼별 누락값 제외한 값을 센다.

size()는 누락값 관계 없이 데이터를 세기 때문에
그룹화된 데이터프레임을 세든,
컬럼을 기준으로 세든
같은 결과의 시리즈가 나오게 된다.
describe
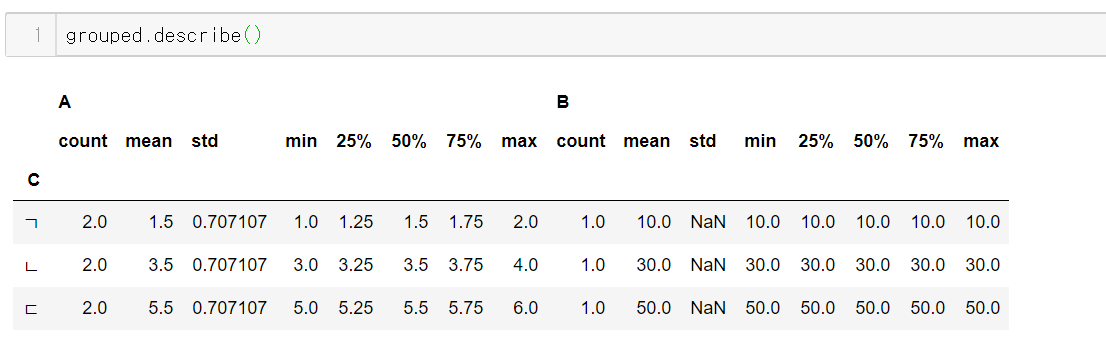
describe를 이용하면 전체적인 요약본을 볼 수 있다.

그냥 describe가 보기 불편하다면 stack을 이용하는 것도 방법이다.
반응형
'Pandas > 응용' 카테고리의 다른 글
| 판다스 - groupby : aggregate (agg 메서드 안의 기준 컬럼, count 이용) (0) | 2020.06.22 |
|---|---|
| 판다스 - groupby : aggregate (0) | 2020.06.22 |
| 판다스 - apply, applymap, pipe(응용3) (0) | 2020.06.22 |
| 판다스 - apply, applymap, pipe(응용2) (0) | 2020.06.21 |
| 판다스 - apply, applymap, pipe(응용1) (0) | 2020.06.21 |



